Life360 访谈
2016 年 3 月 23 日作者 Brian Brazil
这是我们对 Prometheus 用户系列访谈的第一篇,旨在让他们分享评估和使用 Prometheus 的经验。我们的第一位访谈对象是来自 Life360 的 Daniel。
您能介绍一下您自己以及 Life360 的业务吗?
我是 Daniel Ben Yosef,大家也叫我 dby,是 Life360 的一名基础架构工程师。在此之前,我担任系统工程方面的职位已有 9 年了。
Life360 致力于开发帮助家庭成员保持联系的技术,我们是面向家庭的“家庭网络”应用程序。我们为这些家庭提供服务,业务相当繁忙——高峰时期,我们为 7000 万注册家庭每分钟处理 70 万次请求。
![]()
我们在生产环境中管理着大约 20 项服务,主要处理来自移动客户端(Android、iOS 和 Windows Phone)的位置请求,高峰时服务实例超过 150 个。冗余和高可用性是我们的目标,我们力求尽可能保持 100% 的正常运行时间,因为家庭用户信任我们的服务始终可用。
我们的用户数据存储在 MySQL 多主集群和 12 节点的 Cassandra 环中,后者在任何时候都存有大约 4TB 的数据。我们有使用 Go、Python、PHP 编写的服务,并计划将 Java 引入我们的技术栈。我们使用 Consul 进行服务发现,当然,我们的 Prometheus 配置也与之集成。
在使用 Prometheus 之前,您的监控体验是怎样的?
在我们切换到 Prometheus 之前,我们的监控系统包括许多组件,例如:
- Copperegg(现在是 Idera)
- Graphite + Statsd + Grafana
- Sensu
- AWS Cloudwatch
我们主要使用 MySQL、NSQ 和 HAProxy,我们发现上面提到的所有监控解决方案都非常片面,并且需要大量定制才能让它们协同工作。
你们为什么决定研究 Prometheus?
我们切换到 Prometheus 有几个原因,其中之一是我们确实需要更好的监控。
我们关注 Prometheus 已有一段时间了,一直在跟踪并阅读有关其积极开发的资料。在几个月前的某个时间点,我们决定开始评估它是否可以用于生产环境。
概念验证(PoC)的结果令人难以置信。它对 MySQL 的监控覆盖范围非常出色,我们也很喜欢针对 Cassandra 的 JMX 监控,这在过去一直是我们 sorely 缺乏的。
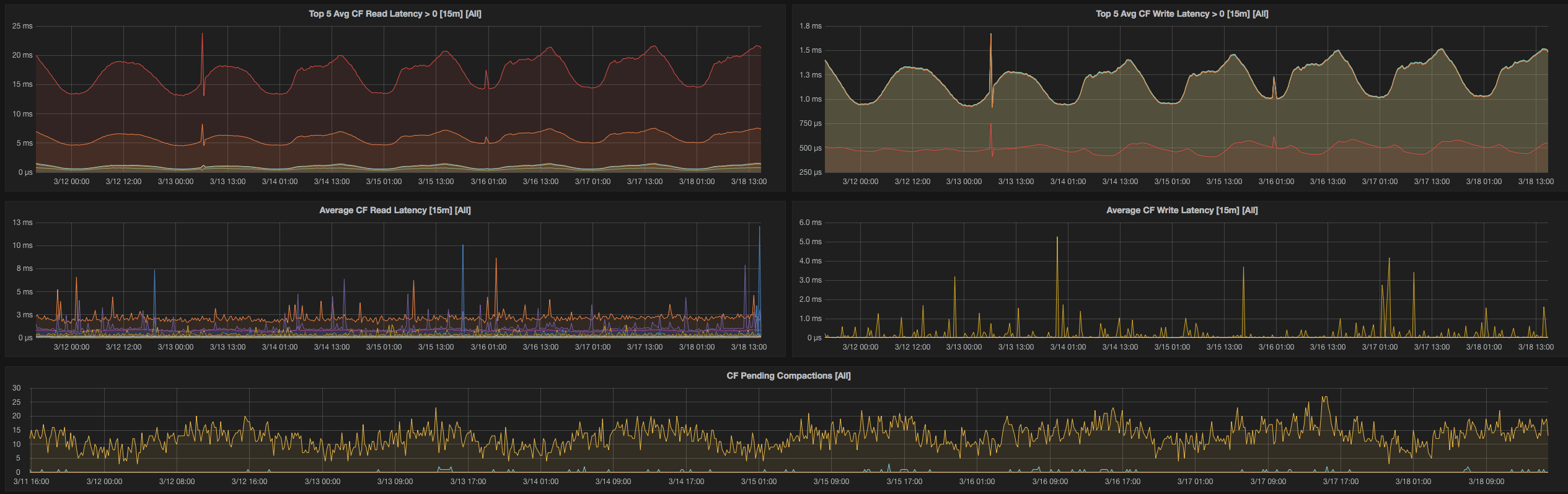
你们是如何过渡的?
我们起初使用一台相对较小的机器(4GB 内存)作为起点。这对于少数服务是有效的,但无法满足我们全部的监控需求。
我们最初也是用 Docker 部署的,但后来慢慢迁移到了一个专用的 r3.2xl 实例(60GB 内存)上,这台机器承载了我们所有的服务监控需求,并保留了 30 天的内存数据。
我们逐步为所有主机引入了 Node Exporter 并构建了 Grafana 图表,直到我们实现了对所有服务的全面覆盖。
我们当时也在考虑使用 InfluxDB 进行长期数据存储,但由于最近的一些变动,这可能不再是一个可行的选项了。
接着,我们为 MySQL、Node、Cloudwatch、HAProxy、JMX、NSQ(用了一些我们自己的代码)、Redis 和 Blackbox(我们自己贡献了代码以添加身份验证头)添加了 exporter。
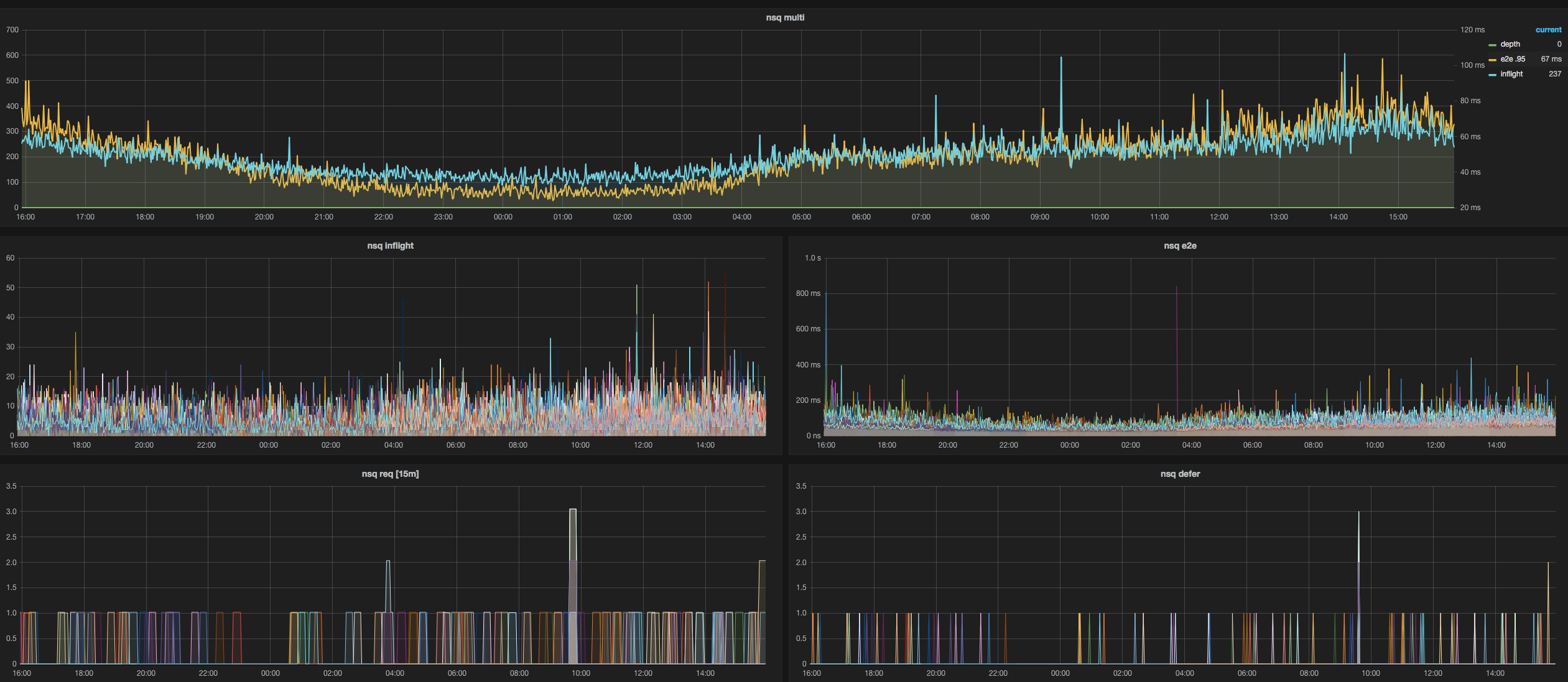
切换后你们看到了哪些改进?
我们首先看到的是可见性和埋点能力的提升。在切换之前,我们开始遇到 Graphite 的可伸缩性问题,而有一个能够直接替代 Graphite 的方案,让利益相关者可以继续使用 Grafana 作为监控工具,这对我们来说非常有价值。如今,我们正专注于利用所有这些数据来检测异常,这些异常最终会成为 Alert Manager 中的告警。
您认为 Life360 和 Prometheus 的未来会是怎样的?
我们目前有一个项目(一个基于 Python 的服务)直接使用了 Prometheus 客户端进行埋点。随着我们构建新的服务,Prometheus 正成为我们进行埋点的首选工具,并将帮助我们获得关于基础架构的极具意义的告警和统计数据。
我们期待与该项目共同成长,并继续做出贡献。
谢谢你,Daniel!Life360 的仪表盘源代码已在 Github 上分享。