Compose 访谈
2016年9月21日作者 Brian Brazil
我们继续对 Prometheus 用户的系列访谈,本期 Compose 将讲述他们从 Graphite 和 InfluxDB 到 Prometheus 的监控之旅。
能介绍一下您自己以及 Compose 的业务吗?
Compose 为全球开发者提供生产就绪的数据库集群即服务。应用开发者只需在我们平台点击几下,就能在几分钟内获得一个多主机、高可用、自动备份且安全的数据库。这些数据库部署会随着需求的增加而自动扩展,这样开发者就可以专注于构建他们出色的应用,而无需费心于数据库的运维。
我们在 AWS、Google Cloud Platform 和 SoftLayer 的每个平台中,都至少有两个区域拥有数十个主机集群。在支持的情况下,每个集群都跨越多个可用区,并容纳了大约 1000 个高可用数据库部署,这些部署都在各自的私有网络中。我们还在计划增加更多的区域和云服务提供商。
在使用 Prometheus 之前,您的监控体验是怎样的?
在采用 Prometheus 之前,我们尝试过多种不同的指标系统。我们尝试的第一个系统是 Graphite,它最初运行得相当不错,但我们需要存储的指标种类数量巨大,加上 Whisper 文件在磁盘上的存储和访问方式,很快就让我们的系统不堪重负。虽然我们知道 Graphite 可以相对容易地进行水平扩展,但这将是一个成本高昂的集群。后来 InfluxDB 看起来更有前景,所以我们开始试用它的早期版本,并且在相当长的一段时间里它都运行良好。再见了,Graphite。
早期版本的 InfluxDB 偶尔会出现数据损坏问题。我们不得不半定期地清除所有指标。这通常对我们来说不是毁灭性的损失,但很烦人。坦白说,那些持续承诺却从未实现的功能让我们感到疲惫。
你们为什么决定研究 Prometheus?
与其他方案相比,它似乎将更高的效率与更简单的操作结合了起来。
基于拉取(Pull-based)的指标收集方式起初让我们感到困惑,但我们很快就意识到了它的好处。最初我们觉得它可能过于笨重,无法在我们的环境中很好地扩展,因为我们通常在每台主机上有数百个带有各自指标的容器。但通过与 Telegraf 结合,我们可以安排每台主机通过一个 Prometheus 抓取目标,来导出其所有容器的指标(以及其整体资源指标)。
你们是如何过渡的?
我们是一家使用 Chef 的公司,所以我们启动了一个拥有大 EBS 卷的大型实例,然后直接使用了一个用于 Prometheus 的社区 Chef cookbook。
当 Prometheus 在一台主机上运行后,我们编写了一个小型的 Ruby 脚本,该脚本使用 Chef API 查询我们所有的主机,并生成一个 Prometheus 目标配置文件。我们将此文件与 file_sd_config 一起使用,以确保所有主机在向 Chef 注册后立即被发现和抓取。得益于 Prometheus 开放的生态系统,我们能够开箱即用地使用 Telegraf,只需一个简单的配置即可直接导出主机级别的指标。
我们当时正在测试单个 Prometheus 的扩展能力极限,等着它崩溃。但它没有!事实上,它处理了我们新基础设施中约 450 台主机每 15 秒抓取一次的主机级指标负载,资源使用率却非常低。
我们每台主机上都有很多容器,所以我们预计一旦添加了所有这些容器的内存使用指标,就必须开始对 Prometheus 进行分片。但 Prometheus 依然平稳运行,没有出现任何问题,也远未达到其资源饱和状态。目前,我们使用一个 m4.xlarge 的 Prometheus 实例和 1TB 的存储空间,每 15 秒监控来自 450 台主机上约 40,000 个容器的超过 400,000 个独立指标。您可以在下面看到我们这台主机的仪表盘。1TB 的 gp2 SSD EBS 卷上的磁盘 IO 最终可能会成为限制因素。我们最初的猜测是,目前的配置已经超额预配了,但我们在收集的指标数量和需要监控的主机/容器数量上都在快速增长。
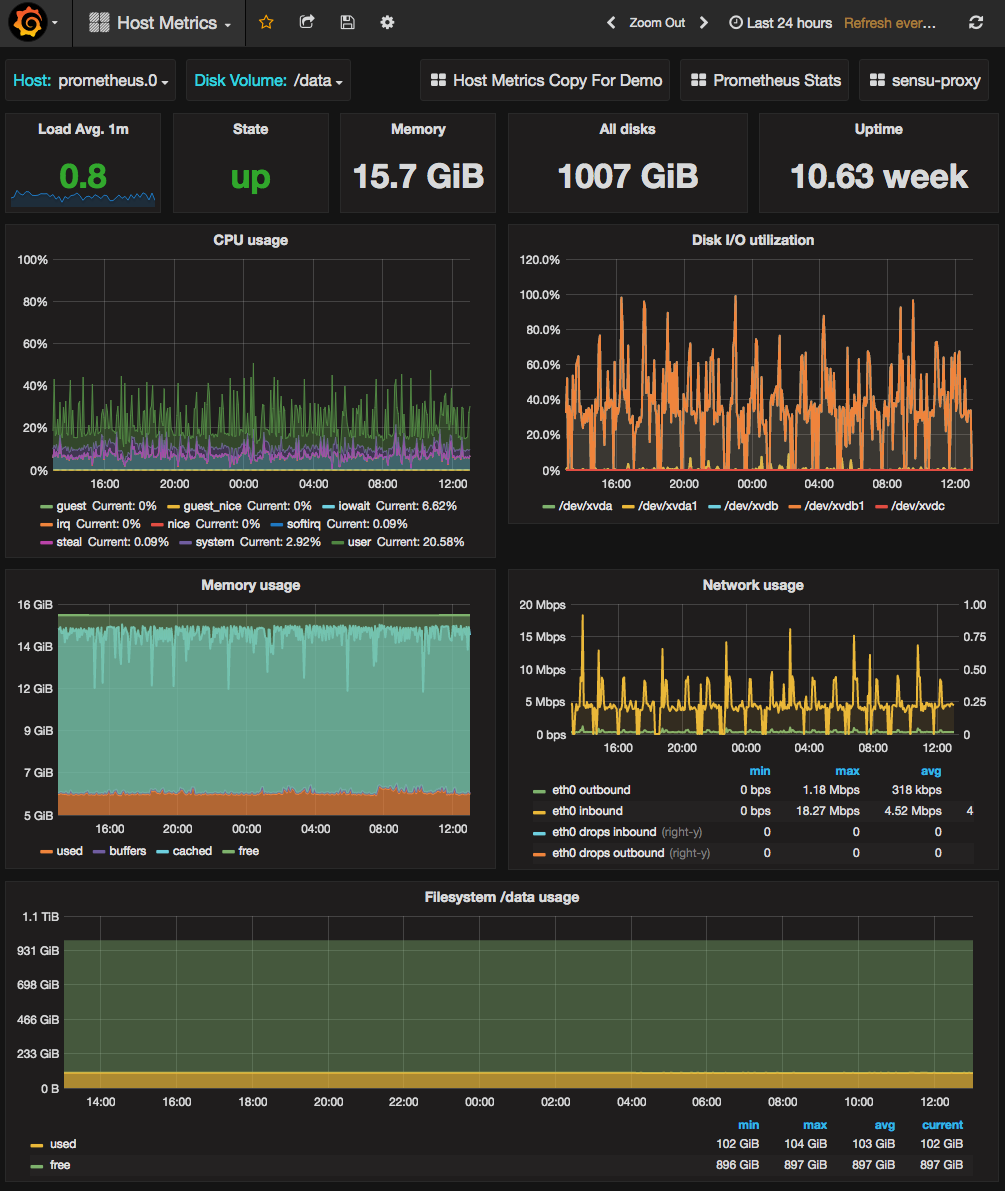
此时,我们用来测试的 Prometheus 服务器已经比我们之前做同样工作的 InfluxDB 集群可靠得多,所以我们做了一些基础工作,使其不再是单点故障。我们添加了另一个相同的节点,抓取所有相同的目标,然后使用 keepalived + DNS 更新添加了一个简单的故障转移方案。这比我们之前的系统具有更高的可用性,所以我们将面向客户的图表切换到使用 Prometheus,并拆除了旧系统。
切换后你们看到了哪些改进?
我们以前的监控设置不可靠且难以管理。有了 Prometheus,我们有了一个能很好地绘制大量指标图表的系统,而且团队成员们突然对使用它的新方法感到兴奋,而不是像以前那样对接触指标系统心存畏惧。
集群也变得更简单了,只有两个相同的节点。随着我们的发展,我们知道将不得不把工作分片到更多的 Prometheus 主机上,并且已经考虑了几种实现方式。
您认为 Compose 和 Prometheus 的未来会是怎样的?
目前,我们只复制了之前系统中已经收集的指标——客户容器的基本内存使用情况以及我们自己运营所需的主机级资源使用情况。下一个合乎逻辑的步骤是让数据库团队能够从数据库容器内部将指标推送到本地的 Telegraf 实例,这样我们就可以记录数据库级别的统计数据,而无需增加需要抓取的目标数量。
我们还有其他几个系统也希望接入 Prometheus 以获得更好的可见性。我们在 Mesos 上运行我们的应用程序,并且已经集成了基本的 Docker 容器指标,这比以前要好,但我们还希望 Mesos 集群中有更多的基础架构组件能记录到中央 Prometheus,这样我们就可以拥有集中的仪表盘,显示从负载均衡器到应用程序指标的所有支持系统健康状况的元素。
最终我们将需要对 Prometheus 进行分片。出于多种原因,我们已经将客户部署分散到许多较小的集群中,因此一个合理的选择是,为每个集群配备一个较小的 Prometheus 服务器(或一对以实现冗余),而不是一个全局的 Prometheus 服务器。
对于大多数报告需求来说,这不是一个大问题,因为我们通常不需要在同一个仪表盘中展示来自不同集群的主机/容器,但我们可能会保留一个小型全局集群,它具有更长的数据保留期,只存储来自每个集群 Prometheus 的少量降采样和聚合后的指标,这些指标通过记录规则(Recording Rules)生成。