iAdvize 访谈
2017年5月17日作者 Brian Brazil
在本系列 Prometheus 用户访谈中,iAdvize 的 Laurent COMMARIEU 谈到了他们如何用 Prometheus 取代了旧有的 Nagios 和 Centreon 监控系统。
您能介绍一下 iAdvize 的业务吗?
我是 Laurent COMMARIEU,iAdvize 的一名系统工程师。我在由5名系统工程师组成的团队中工作,这个团队属于60人的研发部门。我们的主要工作是确保应用程序、服务和底层系统正常运行。我们与开发人员合作,确保他们的代码能够最顺利地投入生产,并在每个步骤提供必要的反馈。这就是监控的重要性所在。
iAdvize 是一个全栈的对话式商务平台。我们为品牌提供一种便捷的方式,使其能够集中与客户互动,无论沟通渠道是聊天、电话、视频、Facebook 页面、Facebook Messenger、Twitter、Instagram、WhatsApp 还是短信等。我们的客户遍布 40个国家的电子商务、银行、旅游、时尚等行业。我们是一家拥有200名员工的国际公司,在法国、英国、德国、西班牙和意大利设有办事处。我们在2015年筹集了1600万美元。
您在使用 Prometheus 之前的监控经验如何?
我于2016年2月加入 iAdvize。此前,我曾在专门从事网络和应用监控的公司工作。我们使用开源软件,如 Nagios、Cacti、Centreon、Zabbix、OpenNMS 等,以及一些非免费的软件,如 HP NNM、IBM Netcool suite、BMC Patrol 等。
iAdvize 以前将监控委托给外部提供商。他们使用 Nagios 和 Centreon 进行24/7监控。这套工具在传统的静态架构(裸机服务器,无虚拟机,无容器)下运行良好。为了完善这个监控堆栈,我们还使用了 Pingdom。
随着我们将单体应用转向微服务架构(使用 Docker),以及我们希望将当前的工作负载迁移到云基础设施提供商,我们因此需要对监控拥有更多的控制权和灵活性。与此同时,iAdvize 招聘了3名新员工,使基础设施团队从2人增加到5人。在旧系统中,向 Centreon 添加新指标至少需要几天甚至一周时间,而且成本高昂(时间和金钱)。
您为什么决定考虑 Prometheus?
我们知道 Nagios 等工具并不是好的选择。当时 Prometheus 正是冉冉升起的新星,我们决定对其进行概念验证 (PoC)。Sensu 最初也在考虑之列,但 Prometheus 似乎对我们的用例更具前景。
我们需要一个能够与我们的服务发现系统 Consul 集成的工具。我们的微服务已经有一个 `/health` 路由;添加一个 `/metrics` 端点非常简单。对于我们使用的几乎所有工具,都有可用的导出器(MySQL、Memcached、Redis、nginx、FPM 等)。
理论上看起来不错。
您是如何完成过渡的?
首先,我们必须说服开发团队(40人)Prometheus 是这项工作的正确工具,并且他们必须为自己的应用程序添加一个导出器。因此,我们对 RabbitMQ 进行了一个小演示,我们安装了一个 RabbitMQ 导出器,并构建了一个简单的 Grafana 仪表盘,以向开发人员显示使用情况指标。我们编写了一个 Python 脚本来创建一些队列并发布/消费消息。
他们看到队列和消息实时出现,感到非常惊讶。在此之前,开发人员无法访问任何监控数据。Centreon 受限于我们的基础设施提供商。如今,iAdvize 的每个人都可以访问 Grafana,并使用 Google Auth 集成进行身份验证。目前有78个活跃账户(从开发团队到首席执行官)。
我们开始使用 Consul 和 cAdvisor 监控现有服务后,我们监控了容器的实际存在。它们通过 Pingdom 检查进行监控,但这还不够。
我们用 Go 开发了一些自定义导出器,用于从我们的数据库(MySQL 和 Redis)中抓取一些业务指标。
很快,我们就能够用 Prometheus 替换所有旧的监控系统。
切换后您看到了哪些改进?
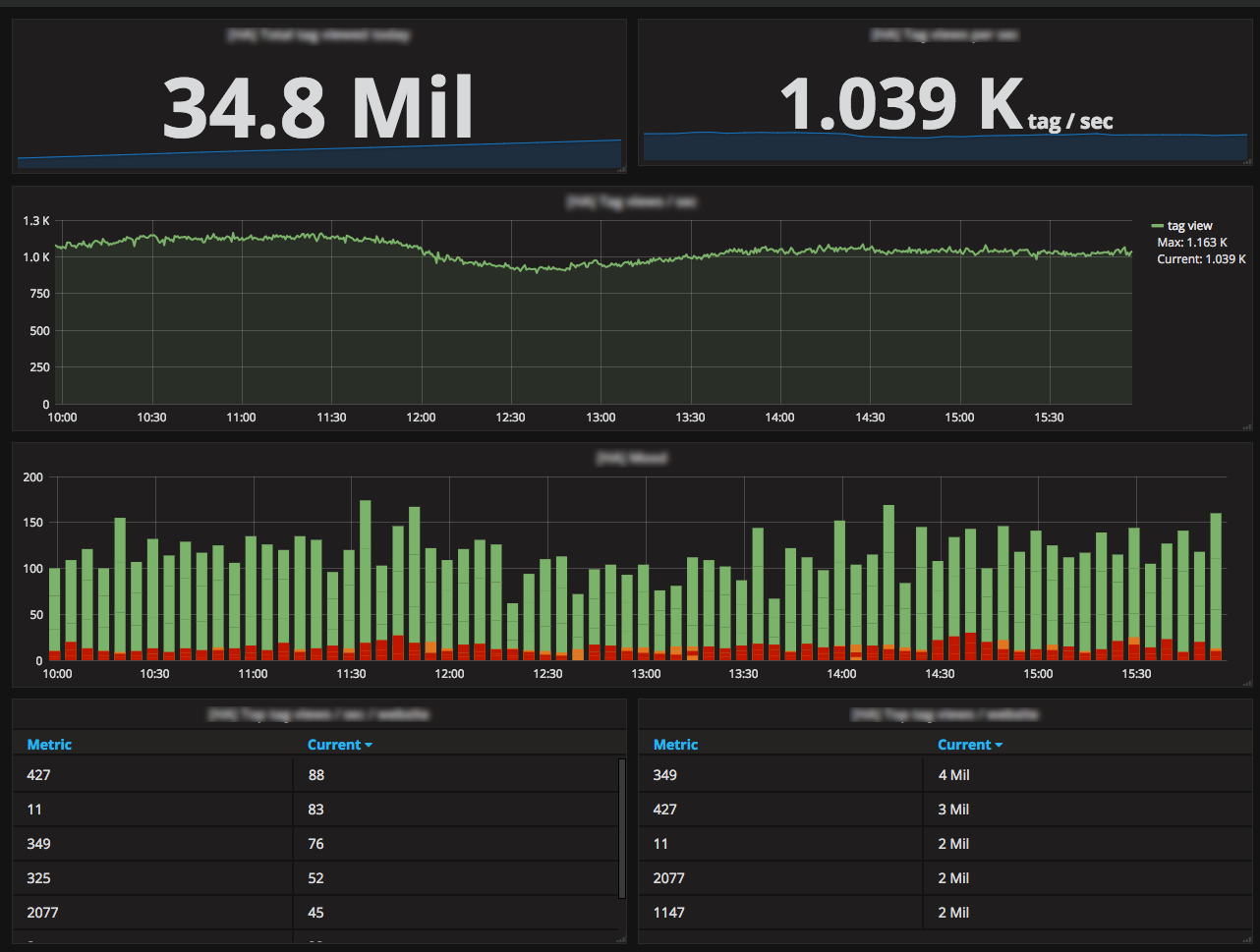
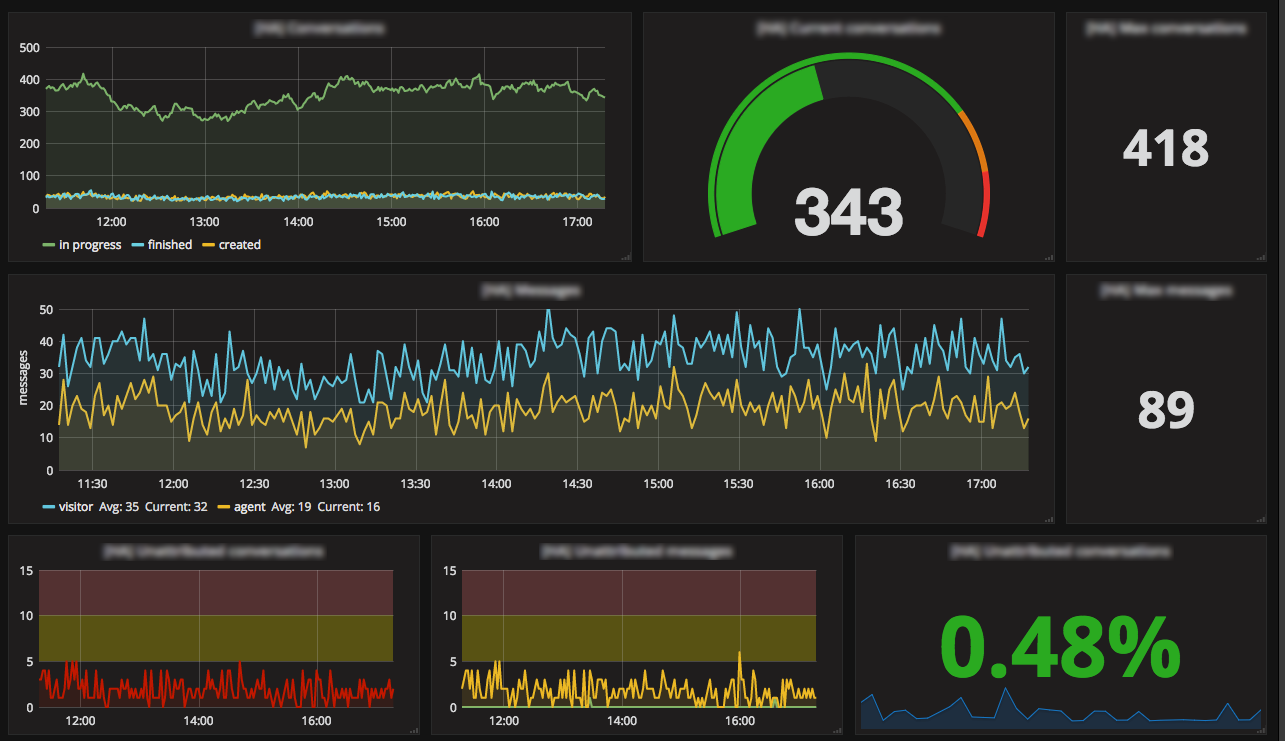
业务指标变得非常受欢迎,在销售期间,每个人都会连接到 Grafana,看看我们能否打破记录。我们监控同时对话的数量、路由错误、在线客服人数、加载 iAdvize 标签的访客数量、API 网关上的调用次数等等。
我们花了一个月的时间,根据 Newrelic 导出器 和 [Percona Grafana 仪表盘] (https://github.com/percona/grafana-dashboards) 的分析,优化了我们的 MySQL 服务器。这是一个巨大的成功,使我们能够发现低效之处并进行优化,从而将数据库大小减少了45%,峰值延迟降低了75%。
要说的还有很多。我们知道 AMQP 队列是否没有消费者,或者是否异常填充。我们知道容器何时重启。
可见性简直太棒了。
那只是针对旧平台而言。
越来越多的微服务将部署到云端,Prometheus 正被用于监控它们。我们使用 Consul 来注册服务,并使用 Prometheus 来发现指标路由。一切都运行得像魔法一样,我们能够构建一个 Grafana 仪表盘,其中包含大量关键的业务、应用程序和系统指标。
我们正在构建一个可扩展的架构,以便使用 Nomad 部署我们的服务。Nomad 将健康的服务注册到 Consul 中,并通过一些标签重命名,我们能够过滤掉带有“metrics=true”标签的服务。这为我们节省了大量部署监控的时间。我们什么都不用做^^。
我们还使用 EC2 服务发现。它与自动扩缩组结合使用非常有用。我们扩缩和回收实例,它们已经受到监控。不再需要等待我们的外部基础设施提供商来发现生产中发生的情况。
我们使用 alertmanager 将一些警报通过短信发送到我们的 Flowdock 中。
您认为 iAdvize 和 Prometheus 的未来会怎样?
- 我们正在等待一种简单的方式,为我们的容量规划添加一个可扩展的长期存储。
- 我们梦想有一天,我们的自动扩缩能由 Prometheus 警报触发。我们希望建立一个基于响应时间和业务指标的自治系统。
- 我曾使用过 Netuitive,它有一个很棒的异常检测功能,并带有自动关联。如果 Prometheus 也有这样的功能就太好了。