Hostinger 访谈
2019 年 2 月 6 日作者 Brian Brazil
我们将继续对 Prometheus 用户进行系列访谈,本期由来自 Hostinger 的 Donatas Abraitis 畅谈他们的监控之旅。
您能介绍一下您自己以及 Hostinger 的业务吗?
我是 Donatas Abraitis,Hostinger 的一名系统工程师。顾名思义,Hostinger 是一家主机托管公司。自 2004 年以来,我们拥有约 3000 万客户,其中包括免费虚拟主机提供商 000webhost.com 项目。
在使用 Prometheus 之前,您的监控体验是怎样的?
在 Hostinger 还是一家小公司时,市面上的开源监控工具只有 Nagios、Cacti 和 Ganglia。这就像跟年轻人讲什么是软盘一样,但 Nagios 和 Cacti 至今仍在开发周期中。
虽然当时还没有自动化工具,但 Bash + Perl 也能胜任。如果你想扩展你的团队和你自己,自动化绝不应被忽视。没有自动化,就需要更多的人工操作。
那时我们大约有 150 台物理服务器。相比之下,到今天我们已有约 2000 台服务器,包括虚拟机和物理机。
对于网络设备,SNMP 仍然被广泛使用。但随着“白盒”交换机的兴起,SNMP 变得不那么必要了,因为常规工具也可以安装在上面。
你可以不使用 SNMP,而是在交换机内部运行 node_exporter 或任何其他 exporter,以人类可读的格式暴露任何你需要的指标。优美胜于丑陋,对吧?
我们使用 CumulusOS,它在我们的环境中主要基于 x86 架构,因此运行任何类型的 Linux 程序都完全没有问题。
你们为什么决定研究 Prometheus?
2015 年,我们开始将所有能自动化的东西都自动化,并将 Prometheus 引入了我们的生态系统。起初,我们只有一个监控服务器,上面运行着 Alertmanager、Pushgateway、Grafana、Graylog 和 rsyslogd。
我们当时也评估了 TICK (Telegraf/InfluxDB/Chronograf/Kapacitor) 技术栈,但我们对它并不满意,因为当时其功能有限,而 Prometheus 在许多方面看起来更简单、实现起来也更成熟。
你们是如何过渡的?
在从旧的监控技术栈(NCG - Nagios/Cacti/Ganglia)过渡期间,我们同时使用了两个系统,最终,我们完全依赖于 Prometheus。
我们的服务集群中大约有 25 个社区指标 exporter,外加一些我们自己编写的,比如 lxc_exporter。我们主要使用 textfile collector 来暴露与业务相关的自定义指标。
切换后你们看到了哪些改进?
新的设置将我们的时间分辨率从 5 分钟提高到了 15 秒,这使我们能够进行精细且相当深入的分析。甚至平均检测时间(MTTD)也减少了 4 倍。
您认为 Hostinger 和 Prometheus 的未来会是怎样?
自 2015 年以来,我们的基础设施规模增长了 N 倍,主要的瓶颈变成了 Prometheus 和 Alertmanager。我们的 Prometheus 占用了大约 2TB 的磁盘空间。因此,如果我们重启或更换维护中的节点,就会暂时丢失监控数据。目前我们运行的是 Prometheus 2.4.2 版本,但我们计划在不久的将来升级到 2.6。我们对性能和 WAL 相关的特性尤其感兴趣。Prometheus 重启需要大约 10-15 分钟,这是不可接受的。另一个问题是,如果单个数据中心宕机,我们同样会丢失监控数据。因此,我们决定实施高可用的监控基础设施:在不同的大洲部署两个 Prometheus 节点和两个 Alertmanager 节点。
我们主要的可视化工具是 Grafana。至关重要的是,当主 Prometheus 节点宕机时,Grafana 能够查询备用节点。这很简单——在前面放一个 HAProxy 并在本地接受连接即可。
另一个问题是:我们如何防止用户(开发人员和其他内部员工)滥用仪表盘,从而导致 Prometheus 节点过载。
或者在主节点宕机时防止备用节点出现惊群问题。
为了达到理想状态,我们试用了 Trickster。它极大地加快了仪表盘的加载速度。它能缓存时间序列数据。在我们的案例中,缓存存放在内存里,但也有更多存储位置可供选择。即使主节点宕机,当你刷新仪表盘时,Trickster 也不会向第二个节点查询它内存中已缓存的时间序列。Trickster 位于 Grafana 和 Prometheus 之间,它只与 Prometheus API 通信。
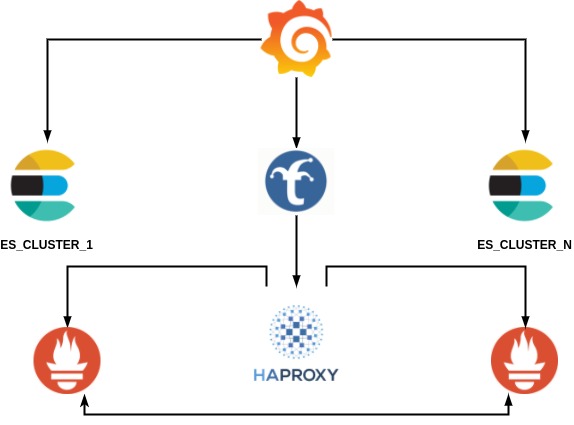
Prometheus 节点是独立的,而 Alertmanager 节点则组成一个集群。如果两个 Alertmanager 都看到相同的警报,它们会进行去重,只触发一次而不是多次。
我们计划运行大量的 blackbox_exporters 来监控每一个 Hostinger 客户的网站,因为任何无法被监控的东西都无法被评估。
我们期待在未来部署更多的 Prometheus 节点,从而在多个 Prometheus 实例之间进行分片。这将使我们不再会因为单个区域的一个实例宕机而出现瓶颈。