编者注:本文是 Prometheus 用户撰写的客座文章。
如果你正在为数万名要求严苛的游戏玩家运营网络,你需要真正了解网络内部正在发生什么。哦,而且一切都需要在短短五天内从零开始构建。
如果你之前从未听说过 DreamHack,这里是介绍:聚集 20,000 人,其中大部分人自带电脑。混合专业游戏 (eSports)、编程比赛和现场音乐会。结果就是世界上最大的、专门致力于所有数字事物的节日。
为了让这样的活动成为可能,需要有大量的基础设施到位。通常这种规模的基础设施需要数月才能建成,但 DreamHack 的工作人员仅用五天就从零开始构建了一切。这当然包括配置网络交换机之类的工作,但也包括构建电力分配、设置餐饮商店,甚至建造实际的桌子。
负责构建和运营所有与网络相关事务的团队正式名称为网络团队,但我们通常称自己为 技术 或 dhtech。本文将重点介绍 dhtech 的工作以及我们在 DreamHack Summer 2015 期间如何使用 Prometheus 来尝试将我们的监控提升到新的水平。
设备
事实证明,要为 10,000 多台计算机构建一个高性能网络,你至少需要相同数量的网络端口。在我们的案例中,这些端口以约 400 台 Cisco 2950 交换机的形式出现。我们称这些为接入层交换机。这些交换机遍布场馆中参与者携带电脑入座的地方。

显然,仅仅将所有这些计算机连接到交换机是不够的。该交换机还需要连接到其他交换机。这就是汇聚层交换机(或称为 dist 交换机)发挥作用的地方。这些交换机接收来自所有接入层交换机的数百条链路,并将它们汇聚成更易于管理的 10 Gbit/s 高容量光纤。然后,这些汇聚层交换机进一步汇聚到我们的核心层,流量在那里被路由到其目的地。
除了所有这些,我们还运营自己的 WiFi 网络、DNS/DHCP 服务器和其他基础设施。完成后,我们的核心层看起来像下面的图片。
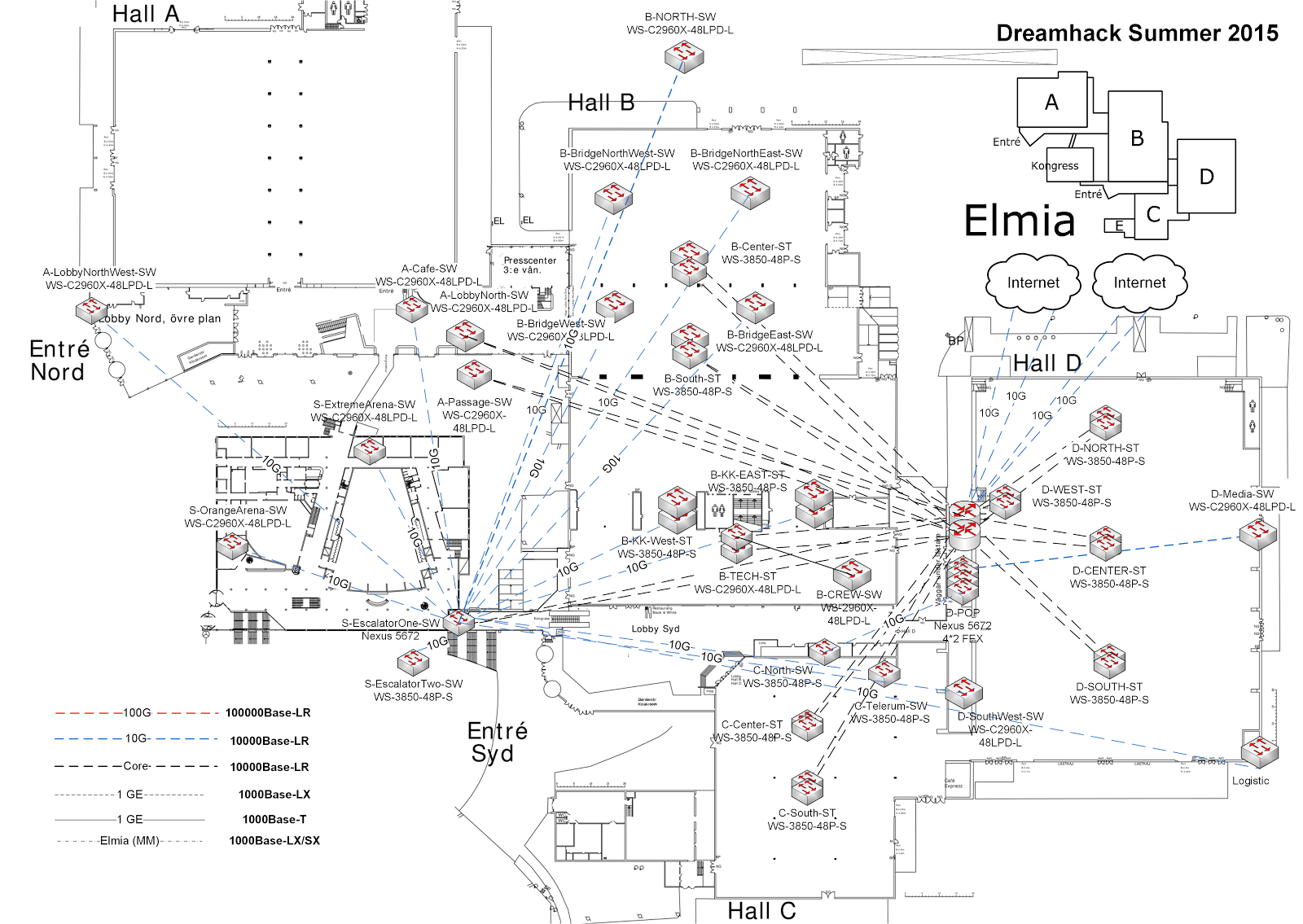
总而言之,这是一长串需要监控的东西,所以让我们回到你在此的原因:我们如何确保知道正在发生什么?
介绍:dhmon
dhmon 是系统的统称,这些系统不仅监控网络,还允许其他团队收集他们想要的任何指标。
由于网络需要在五天内建成,监控系统易于设置并在需要进行最后一刻基础设施变更(例如添加或移除设备)时保持同步至关重要。当我们开始构建网络时,我们需要尽快进行监控,以便能够发现设备或我们未预见的任何其他问题。
过去,我们尝试过使用一些常用的软件组合,例如 Cacti、SNMPc 和 Opsview 等。虽然这些软件也能工作,但它们侧重于封闭系统,只提供了最低限度的功能。几年前,团队中的几个人说:“够了,我们可以做得更好!”于是开始编写自定义监控解决方案。
当时选择有限。多年来,系统从使用 Graphite(可扩展性问题)、自定义 Cassandra 存储(复杂性高)和 InfluxDB(软件不成熟)最终转向使用 Prometheus。我早在 2014 年遇到 Julius Volz 时就第一次了解了 Prometheus,从那时起就一直渴望尝试它。今年夏天,我们终于用 Prometheus 替换了我们编写的基于 InfluxDB 的自定义指标存储。剧透:我们不会再回头了。
架构
监控解决方案由三个层组成:采集、存储、展示。我们最关键的采集器是 snmpcollector (SNMP) 和 ipplan-pinger (ICMP),紧随其后的是 dhcpinfo (DHCP 租约统计)。我们还有一些脚本将其他系统的统计信息转储到 node_exporter 的 textfile 采集器中。
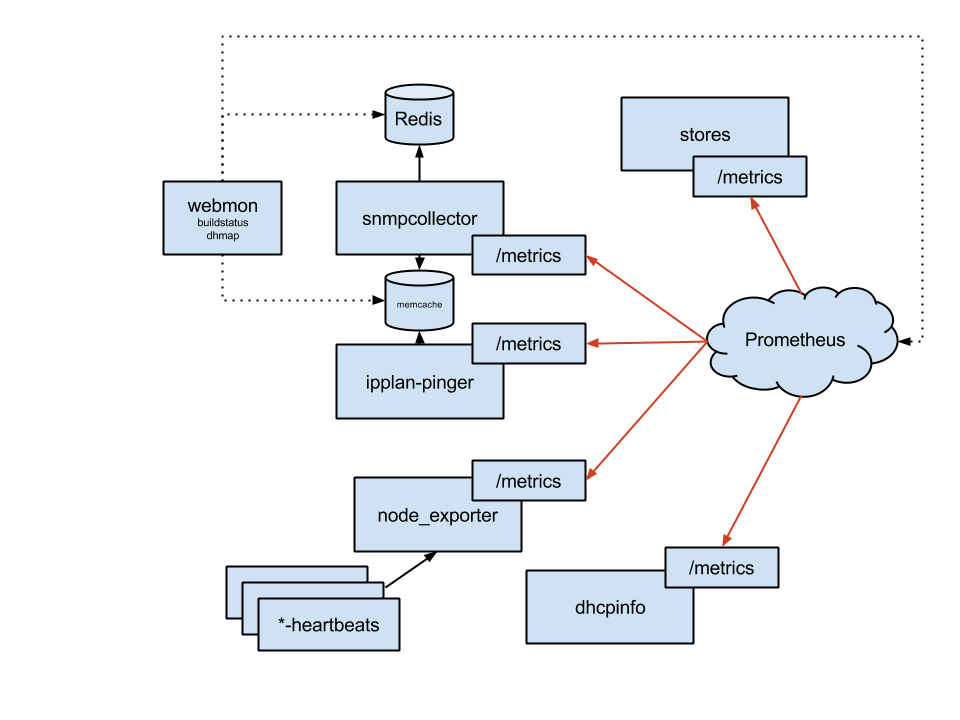
我们使用 Prometheus 作为中央时间序列存储和查询引擎,但我们也使用 Redis 和 memcached 来导出我们收集但无法以合理方式存储在 Prometheus 中的二进制信息的快照视图,或者在我们想要访问非常新的数据时使用它们。
一个这样的例子在我们的展示层。我们使用 dhmap Web 应用程序来获取接入层交换机整体健康状况的概览。为了有效地解决错误,我们需要从数据采集到展示的延迟在约 10 秒以内。我们的目标是在客户注意到问题之前,或者至少在他们去找支持人员报告问题之前解决问题。因此,我们从一开始就使用 memcached 来访问最新的网络快照。
今年,我们继续使用 memcached 处理低延迟数据,而使用 Prometheus 处理所有历史数据或对延迟不敏感的数据。做出这个决定只是因为我们不确定 Prometheus 在非常短的采样间隔下的性能如何。最后,我们发现没有理由不能将 Prometheus 也用于这些数据——我们肯定会在下一次 DreamHack 尝试用 Prometheus 替换我们的 memcached。
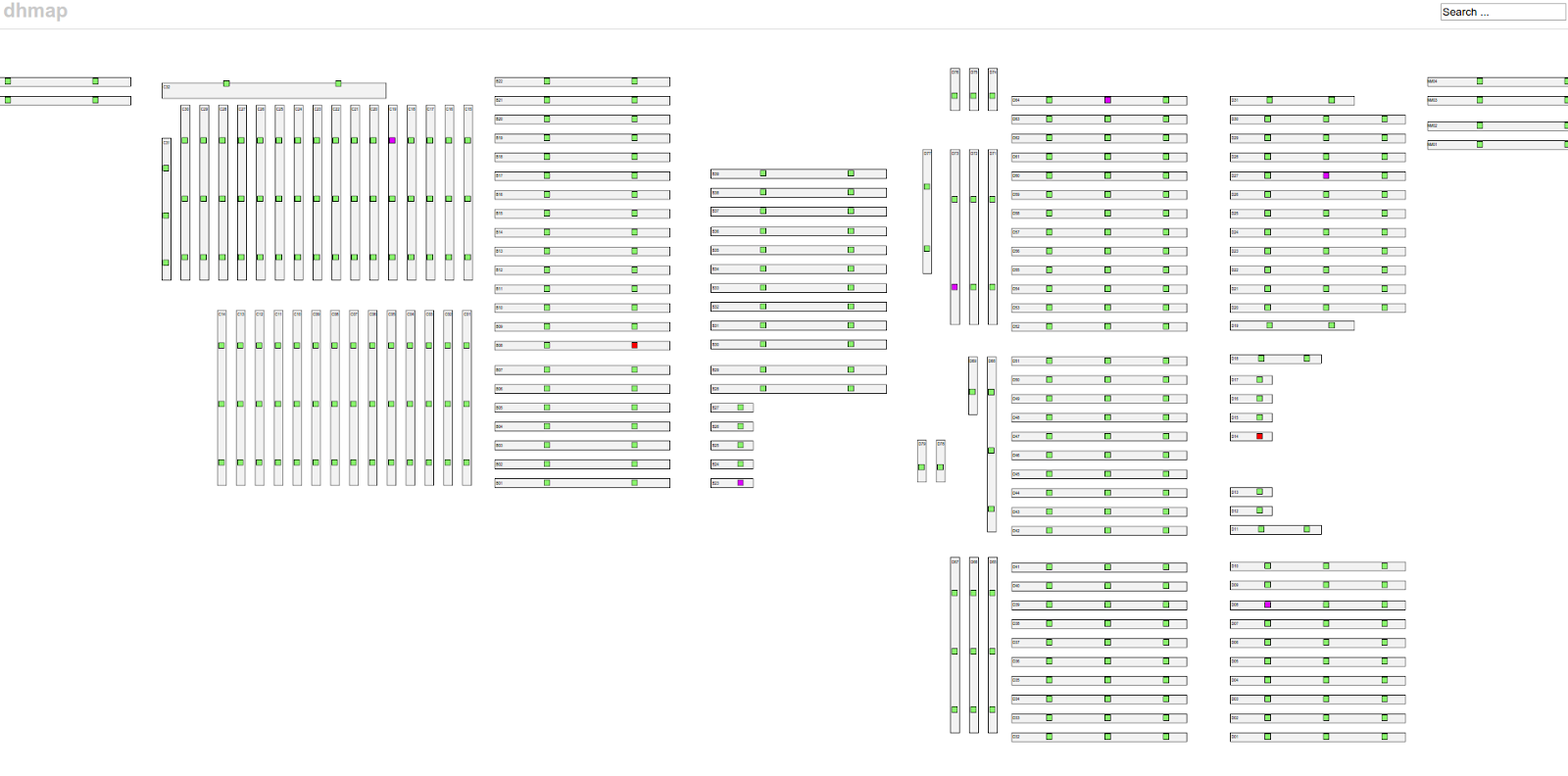
Prometheus 设置
到目前为止被称作 Prometheus 的这部分实际上由三个产品组成:Prometheus、PromDash 和 Alertmanager。设置相当基础,所有三个组件都运行在同一台主机上。一切都通过一个充当反向代理的 Apache Web 服务器提供服务。
ProxyPass /prometheus http://localhost:9090/prometheus
ProxyPass /alertmanager http://localhost:9093/alertmanager
ProxyPass /dash http://localhost:3000/dash
探索网络
Prometheus 拥有强大的查询引擎,可以让你利用从网络各处收集的流式信息做很多很酷的事情。然而,有时查询需要处理的数据太多,无法在合理的时间内完成。当我们想要绘制总共约 18,000 条链路中利用率最高的 5 条链路的图表时,就遇到了这种情况。虽然查询成功了,但它所需的时间大致等于我们设置的超时限制,这意味着它既慢又不稳定。我们决定使用 Prometheus 的记录规则来预计算繁重的查询。
precomputed_link_utilization_percent = rate(ifHCOutOctets{layer!='access'}[10m])*8/1000/1000
/ on (device,interface,alias)
ifHighSpeed{layer!='access'}
在此之后,运行 topk(5, precomputed_link_utilization_percent) 变得非常快。
反应式:告警
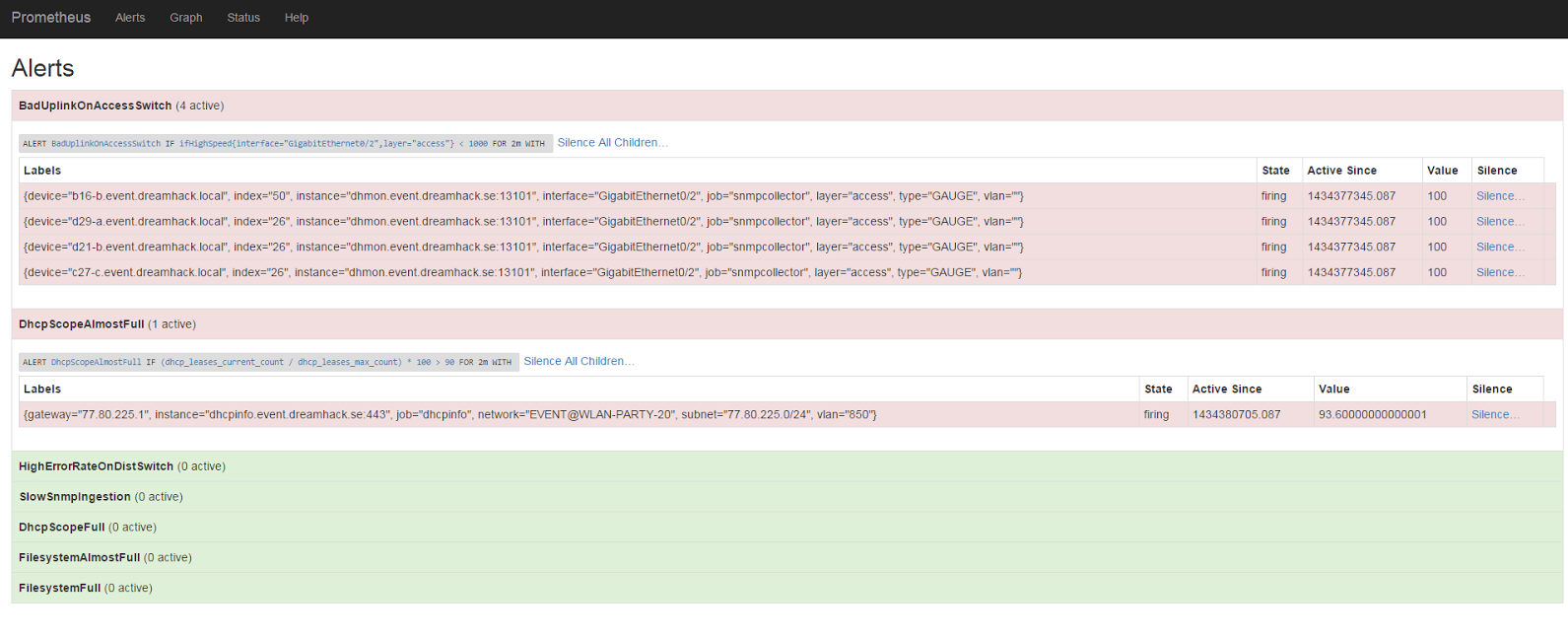
因此,在这个阶段,我们有了可以查询网络状态的东西。既然我们是人,我们不想把时间都花在不断运行查询来查看一切是否正常运行上,所以显然我们需要告警。
例如:我们知道我们所有的接入层交换机都使用 GigabitEthernet0/2 作为上行链路。有时,网络电缆存放时间过长会氧化,无法协商到我们想要的完整 1000 Mbps 速率。
网络端口的协商速率可以在 SNMP OID IF-MIB::ifHighSpeed 中找到。然而,熟悉 SNMP 的人会知道,这个 OID 是由任意的接口索引来索引的。为了理解这个索引,我们需要将其与 SNMP OID IF-MIB::ifDescr 中的数据进行交叉引用,以检索实际的接口名称。
幸运的是,我们的 snmpcollector 在生成 Prometheus 指标时支持这种交叉引用。这使我们能够以一种简单的方式不仅查询数据,还可以定义有用的告警。在我们的设置中,我们将 SNMP 采集配置为使用 ifDescr 注释 IF-MIB::ifTable 和 IF-MIB::ifXTable OID 下的任何指标。这在我们现在需要指定只关注 GigabitEthernet0/2 端口而不是其他接口时会派上用场。
让我们看看这样的告警定义是什么样子的。
ALERT BadUplinkOnAccessSwitch
IF ifHighSpeed{layer='access', interface='GigabitEthernet0/2'} < 1000 FOR 2m
SUMMARY "Interface linking at {{$value}} Mbps"
DESCRIPTION "Interface {{$labels.interface}} on {{$labels.device}} linking at {{$value}} Mbps"
完成!现在,如果交换机的上行链路突然以非最优速率连接,我们将收到告警。
让我们再看看 DHCP 范围几乎满时的告警是什么样子的。
ALERT DhcpScopeAlmostFull
IF ceil((dhcp_leases_current_count / dhcp_leases_max_count)*100) > 90 FOR 2m
SUMMARY "DHCP scope {{$labels.network}} is almost full"
DESCRIPTION "DHCP scope {{$labels.network}} is {{$value}}% full"
我们发现定义告警的语法即使对于没有 Prometheus 或时间序列数据库经验的人来说也很容易阅读和理解。
主动式:仪表盘
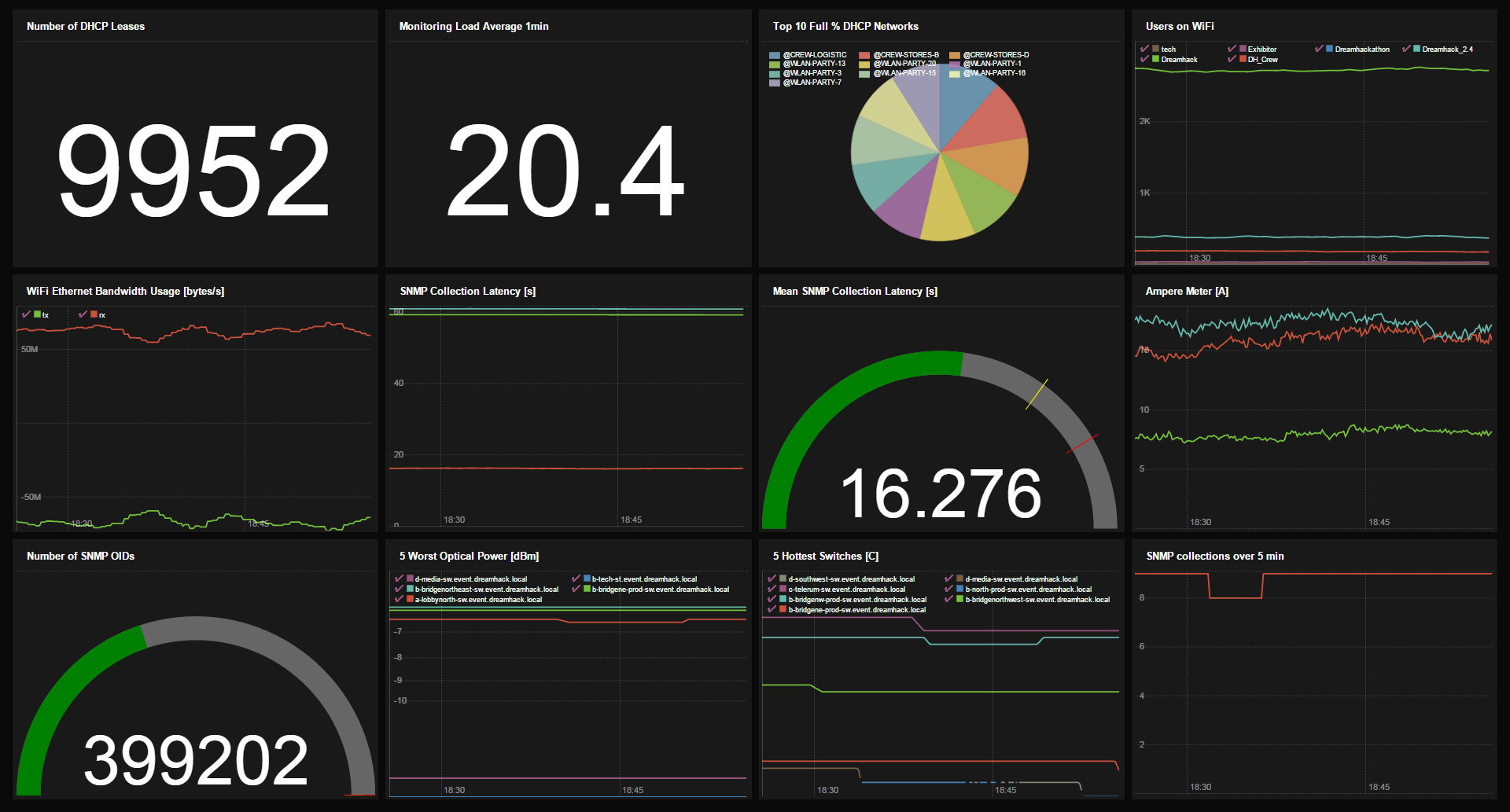
告警是监控的重要组成部分,但有时你只是想对网络的健康状况有一个很好的概览。为了实现这一点,我们使用了 PromDash。每当有人向我们询问网络方面的问题时,我们就会编写一个查询来获取答案,并将其保存为仪表盘小部件。然后,我们将最有趣的那些添加到我们自豪地展示的概览仪表盘中。
未来
改变任何系统的核心部分都是一项复杂的工作,我们很高兴在一个活动中就成功集成了 Prometheus,但毫无疑问还有很多地方可以改进。有些方面相当基础:使用更多预计算指标来提高性能、增加更多告警以及调整现有告警。另一个方面是让操作员更容易使用:创建一个适合我们网络运营中心 (NOC) 的告警仪表盘,弄清楚我们是否要呼叫值班人员,或者只是让 NOC 升级告警。
我们计划增加一些更大的功能:syslog 分析(我们有很多 syslog!)、来自入侵检测系统的告警、与我们的 Puppet 设置集成,以及在 DreamHack 不同团队之间进行更广泛的集成。我们成功创建了一个概念验证,将来自一个电流传感器的电流数据纳入我们的监控中,这样很容易看出设备是否出现故障或者是否根本没有电了。我们还在努力与活动商店中使用的销售点系统集成。谁不想绘制冰淇淋销售图表呢?
最后,并非团队运营的所有服务都在现场,有些甚至在活动结束后仍全天候运行。我们也想用 Prometheus 监控这些服务,并且从长远来看,当 Prometheus 支持联邦功能时,利用场外 Prometheus 复制活动现场 Prometheus 的指标。
结语
我们对 Prometheus 感到非常兴奋,以及它从零开始设置可扩展的监控和告警是多么容易。
非常感谢活动期间在 FreeNode 上的 #prometheus 频道中帮助我们的所有人。特别感谢 Brian Brazil、Fabian Reinartz 和 Julius Volz。感谢你们的帮助,即使在我们显然没有足够彻底地阅读文档的情况下也是如此。
最后,dhmon 全部是开源的,所以如果你有兴趣,可以去 https://github.com/dhtech/ 看看。如果你想参与其中,只需前往 QuakeNet 上的 #dreamhack 频道与我们聊聊。谁知道呢,也许你会帮助我们构建下一个 DreamHack?