这是 Prometheus 用户访谈系列的第二篇,旨在让他们分享评估和使用 Prometheus 的经验。
您能介绍一下自己和 ShowMax 的业务吗?
我是 Antonin Kral,负责 ShowMax 的研究和架构工作。在此之前,我曾担任架构师和 CTO 职位达 12 年。
ShowMax 是一项订阅点播视频服务,于 2015 年在南非推出。我们拥有庞大的内容目录,包含 20,000 多集电视剧和电影。我们的服务目前在全球 65 个国家/地区可用。当知名度更高的竞争对手在美国和欧洲竞争时,ShowMax 正在应对一个更困难的问题:如何在撒哈拉以南非洲一个连接状况不佳的村庄里畅快追剧?全球已有 35% 的视频是流媒体播放的,但仍有许多地方这场革命尚未触及。
![]()
我们管理着大约 50 个服务,这些服务主要运行在围绕 CoreOS 构建的私有集群上。它们主要处理来自客户端(Android、iOS、AppleTV、JavaScript、Samsung TV、LG TV 等)的 API 请求,其中一些用于内部。最大的内部流水线之一是视频编码,处理大量摄入批次时可以占用 400 多台物理服务器。
我们的大多数后端服务是用 Ruby、Go 或 Python 编写的。在用 Ruby 编写应用程序时,我们使用 EventMachine(MRI 上使用 Goliath,JRuby 上使用 Puma)。Go 通常用于需要高吞吐量且业务逻辑不多的应用程序。对于用 Python 编写的服务,我们对 Falcon 非常满意。数据存储在 PostgreSQL 和 ElasticSearch 集群中。我们使用 etcd 和自定义工具配置 Varnish 来路由请求。
您在使用 Prometheus 之前的监控经验是怎样的?
监控系统的主要用例是
- 主动监控和探测(通过 Icinga)
- 指标采集和基于这些指标创建告警(现在使用 Prometheus)
- 从后端服务采集日志
- 从应用程序采集事件和日志
最后两个用例通过我们的日志基础设施处理。它由运行在服务容器中的收集器组成,该收集器监听本地 Unix socket。应用程序使用该 socket 将消息发送到外部。消息通过 RabbitMQ 服务器传输给消费者。消费者是自定义编写的或基于 hekad 的。主要的メッセージ 流之一是流向服务 ElasticSearch 集群,这使得 Kibana 和临时搜索可以访问日志。我们还将所有处理过的事件保存到 GlusterFS 以进行归档和/或进一步处理。
我们曾经并行运行两个指标采集流水线。第一个基于 Collectd + StatsD + Graphite + Grafana,另一个使用 Collectd + OpenTSDB。我们在这两个流水线方面都遇到了相当大的困难。我们不得不处理 Graphite 的 I/O 瓶颈,或者 OpenTSDB 的复杂性和不足的工具。
您为什么决定研究 Prometheus?
在从我们以前监控系统的问题中吸取教训后,我们寻找替代方案。只有少数解决方案进入了我们的候选名单。Prometheus 是最早的之一,因为我们当时的运维负责人 Jiri Brunclik 从 Google 的前同事那里得到了关于该系统的个人推荐。
概念验证进行得很顺利。我们很快就建立了一个可工作的系统。我们还评估了 InfluxDB 作为主系统以及 Prometheus 的长期存储。但由于最近的发展,这对我们来说可能不再是一个可行的选择。
您是如何过渡的?
我们最初在一台服务服务器上使用 LXC 容器开始,但很快就转向了 Hetzner 的一台专用服务器,我们在那里托管了大部分服务。我们使用的是 PX70-SSD,它是配备 32GB RAM 的 Intel® Xeon® E3-1270 v3 Quad-Core Haswell,因此我们有足够的性能来运行 Prometheus。SSD 使我们能够将保留期设置为 120 天。我们的日志基础设施围绕着在本地获取日志(通过 Unix socket 接收)然后将它们推送到各个 worker 构建。
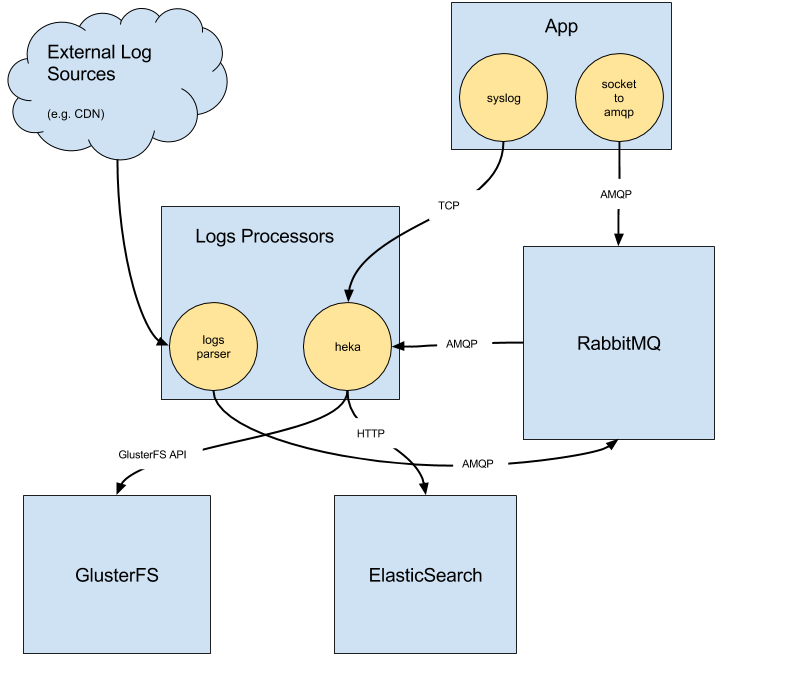
有了这个基础设施,推送指标就成了自然的选择了(尤其是在使用 Prometheus 之前)。另一方面,Prometheus 主要围绕抓取指标的范式设计。我们最初想保持一致,将所有指标推送到 Prometheus。我们创建了一个名为 prometheus-pusher 的 Go 守护进程。它负责从本地 exporter 抓取指标并将其推送到 Pushgateway。推送指标有一些积极方面(例如简化服务发现),但也有不少缺点(例如难以区分网络分区和崩溃的服务)。我们已将 Prometheus-pusher 发布到 GitHub,您可以自行尝试。
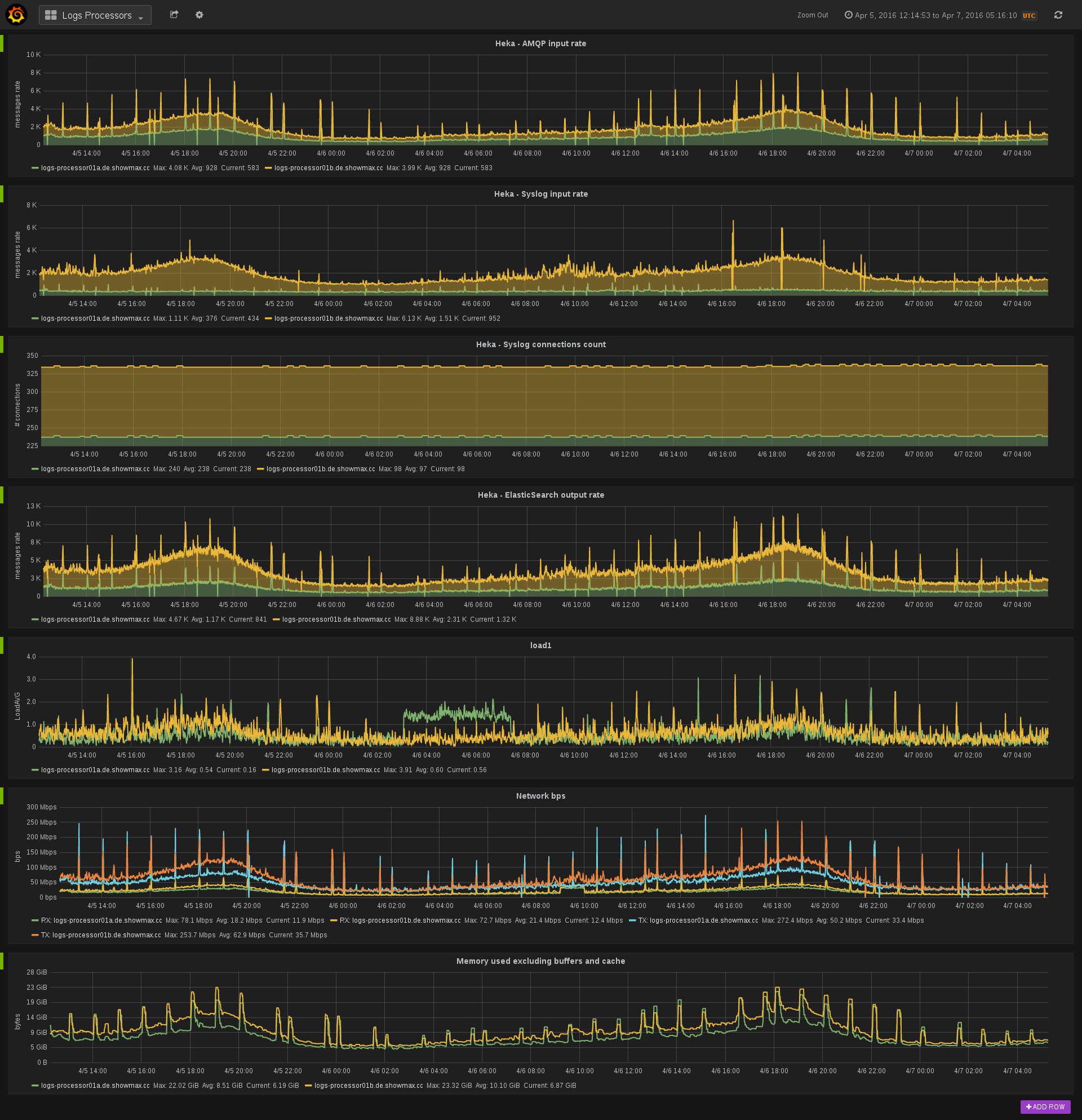
下一步是我们弄清楚如何管理仪表盘和图表。我们喜欢 Grafana 的集成,但不太喜欢 Grafana 管理仪表盘配置的方式。我们在 Docker 容器中运行 Grafana,因此任何更改都应该保留在容器外部。另一个问题是 Grafana 缺乏变更跟踪。
因此,我们决定编写一个生成器,它接收在 git 中维护的 YAML,并为 Grafana 仪表盘生成 JSON 配置。它还能够将仪表盘部署到在新容器中启动的 Grafana,而无需将更改持久化到容器中。这为您提供了自动化、可重复性和审计功能。
我们很高兴宣布,该工具现已在 GitHub 上以 Apache 2.0 许可证发布。
切换后您看到了哪些改进?
我们立即看到的一个改进是 Prometheus 的稳定性。在此之前,我们一直在与 Graphite 的稳定性和可扩展性作斗争,因此解决了这个问题对我们来说是一个巨大的胜利。此外,Prometheus 的速度和稳定性使开发人员可以非常轻松地访问指标。Prometheus 确实在帮助我们拥抱 DevOps 文化。
我们的后端开发人员 Tomas Cerevka 正在使用 JRuby 测试新版本的服务。他需要快速查看该特定服务的堆消耗情况。他能够迅速获得该信息。对我们来说,这种速度至关重要。
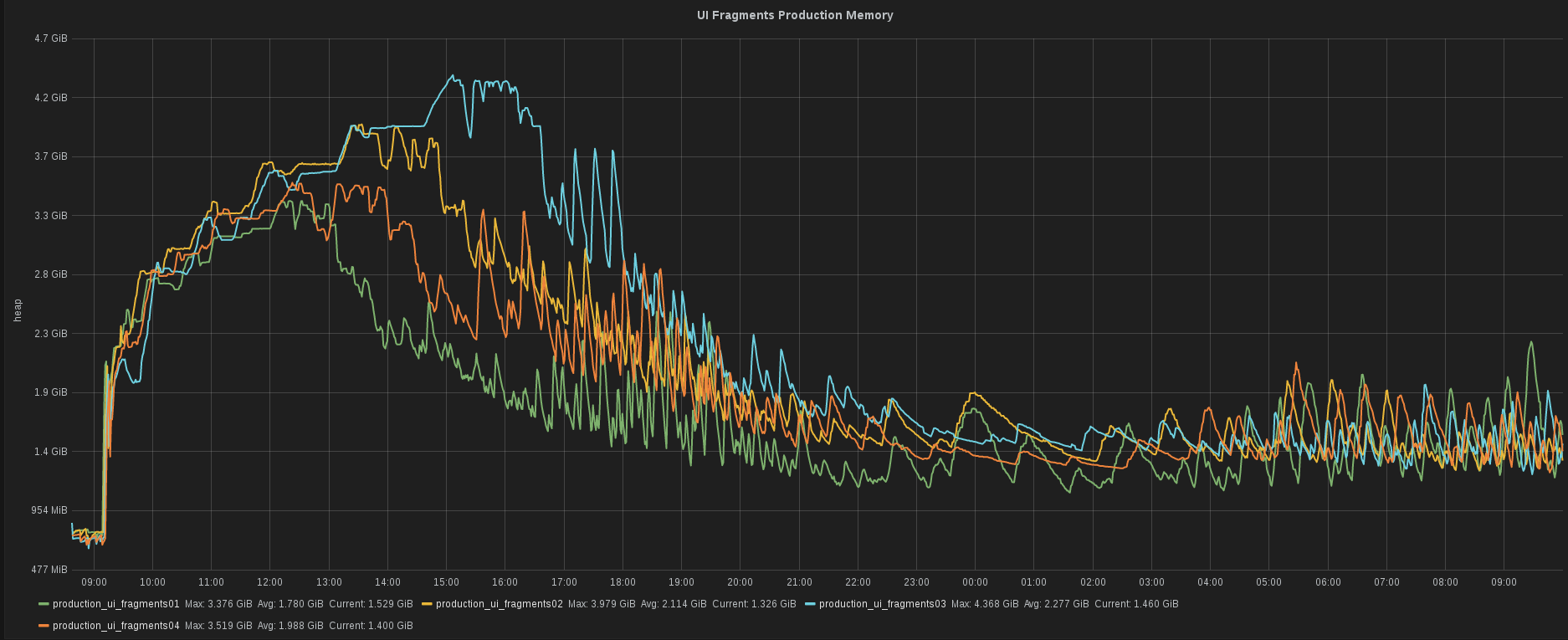
您认为 ShowMax 和 Prometheus 的未来是怎样的?
Prometheus 已成为 ShowMax 监控不可或缺的一部分,在可预见的未来将一直伴随我们。我们已将整个指标存储替换为 Prometheus,但摄入链仍然是基于推送的。因此,我们正在考虑遵循 Prometheus 的最佳实践,并切换到拉取模型。
我们也已经尝试过告警。我们希望在这个主题上投入更多时间,并制定越来越复杂的告警规则。