新的 Prometheus 版本 2.13.0 已经可用,一如既往地包含许多修复和改进。您可以在此处阅读更改内容。然而,有一个一些项目和用户期待已久的功能:分块、流式版本的远程读 API。
在本文中,我想深入介绍我们在远程协议中更改了什么、为什么更改以及如何有效使用它。
远程 API
自 1.x 版本以来,Prometheus 能够使用远程 API直接与其存储交互。
此 API 允许第三方系统通过两种方法与指标数据交互
- 写 - 接收 Prometheus 推送的样本
- 读 - 从 Prometheus 拉取样本

这两种方法都使用 HTTP,消息采用 protobufs 编码。这两种方法的请求和响应都使用 snappy 进行压缩。
远程写
这是将 Prometheus 数据复制到第三方系统的最常用方法。在这种模式下,Prometheus 通过定期向给定端点发送一批样本来流式传输样本。
远程写最近在三月通过 基于 WAL 的远程写 得到了大幅改进,提高了可靠性和资源消耗。值得注意的是,此处提及的几乎所有第三方集成都支持远程写。
远程读
读方法不太常用。它于 2017 年 3 月(服务器端)添加,自那时以来没有进行过重大开发。
Prometheus 2.13.0 版本包含对读 API 中已知资源瓶颈的修复。本文将重点介绍这些改进。
远程读的关键思想是允许直接查询 Prometheus 存储(TSDB),而无需进行 PromQL 求值。它类似于 PromQL 引擎用于从存储中检索数据的 Querier 接口。
这本质上允许读取 Prometheus 收集的 TSDB 中的时间序列。远程读的主要用例包括
- Prometheus 在不同数据格式之间的无缝升级,即一个 Prometheus 从另一个 Prometheus 读取。
- Prometheus 能够从第三方长期存储系统(如 InfluxDB)读取数据。
- 第三方系统从 Prometheus 查询数据,如 Thanos。
远程读 API 暴露了一个简单的 HTTP 端点,期望以下 protobuf 负载
message ReadRequest {
repeated Query queries = 1;
}
message Query {
int64 start_timestamp_ms = 1;
int64 end_timestamp_ms = 2;
repeated prometheus.LabelMatcher matchers = 3;
prometheus.ReadHints hints = 4;
}
通过此负载,客户端可以请求匹配给定 matchers 以及带有 end 和 start 的时间范围内的特定序列。
响应同样简单
message ReadResponse {
// In same order as the request's queries.
repeated QueryResult results = 1;
}
message Sample {
double value = 1;
int64 timestamp = 2;
}
message TimeSeries {
repeated Label labels = 1;
repeated Sample samples = 2;
}
message QueryResult {
repeated prometheus.TimeSeries timeseries = 1;
}
远程读返回匹配的时间序列及其原始的值和时间戳样本。
问题陈述
对于这样一个简单的远程读,存在两个关键问题。它易于使用和理解,但在我们定义的 protobuf 格式的单个 HTTP 请求中没有流式传输功能。其次,响应包含原始样本(float64 值和 int64 时间戳),而不是用于在 TSDB 内部存储指标的编码压缩样本批次,称为“块”(chunks)。
没有流式传输的远程读服务器算法是
- 解析请求。
- 从 TSDB 选择指标。
- 对于所有已解码序列
- 对于所有样本
- 添加到响应 protobuf
- 对于所有样本
- 编码响应。
- 使用 Snappy 压缩。
- 发送回 HTTP 响应。
远程读的整个响应必须以原始、未压缩的格式进行缓冲,以便在将其发送到客户端之前将其编码为潜在巨大的 protobuf 消息。然后,整个响应必须再次在客户端完全缓冲,才能从接收到的 protobuf 中解码它。只有在那之后,客户端才能使用原始样本。
这意味着什么?这意味着,例如,仅匹配 10,000 个序列的 8 小时请求可能需要客户端和服务器分别分配多达 2.5GB 的内存!
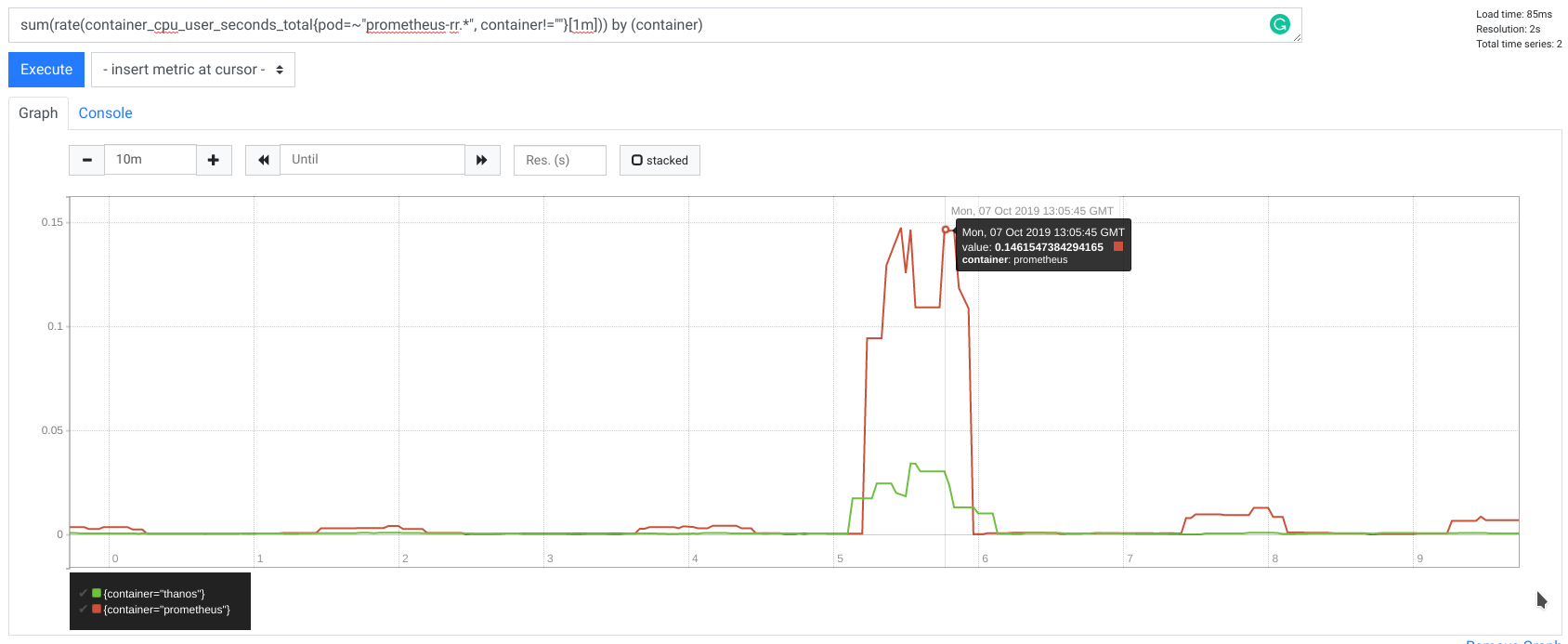
以下是 Prometheus 和 Thanos Sidecar(远程读客户端)在远程读请求期间的内存使用指标
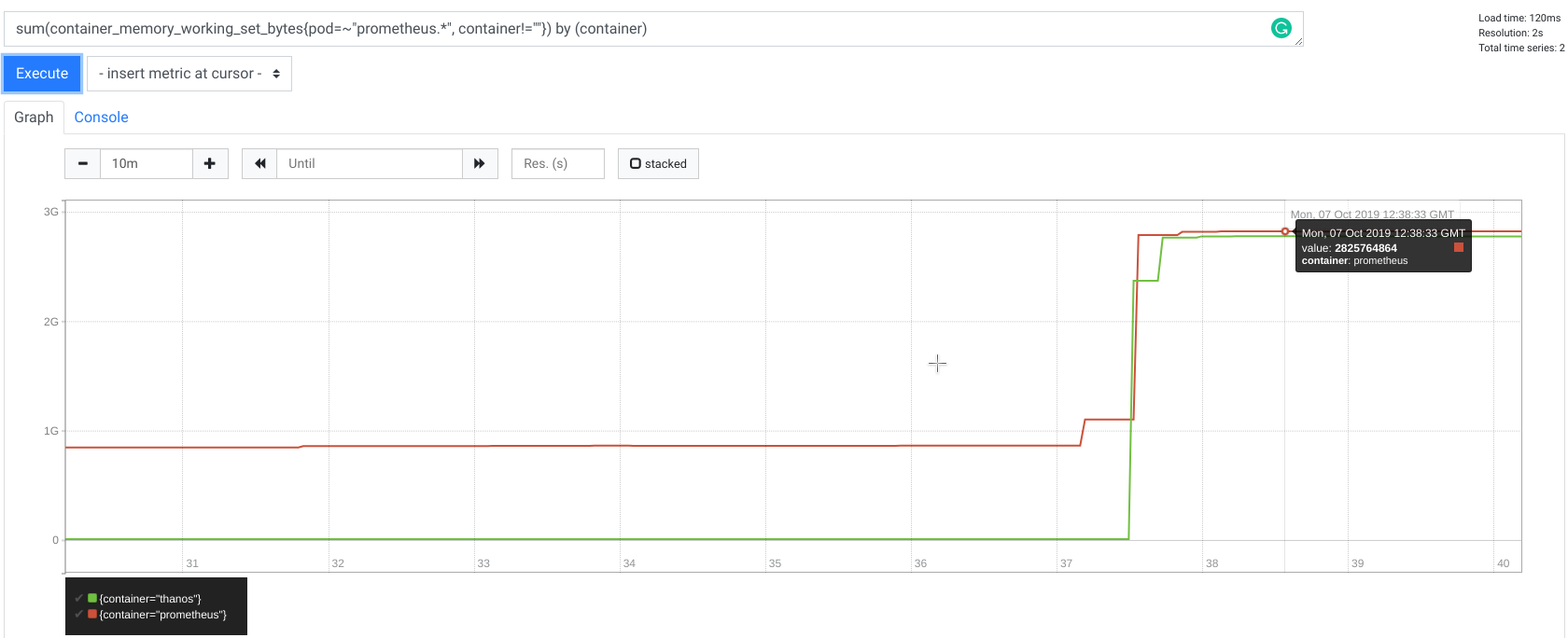
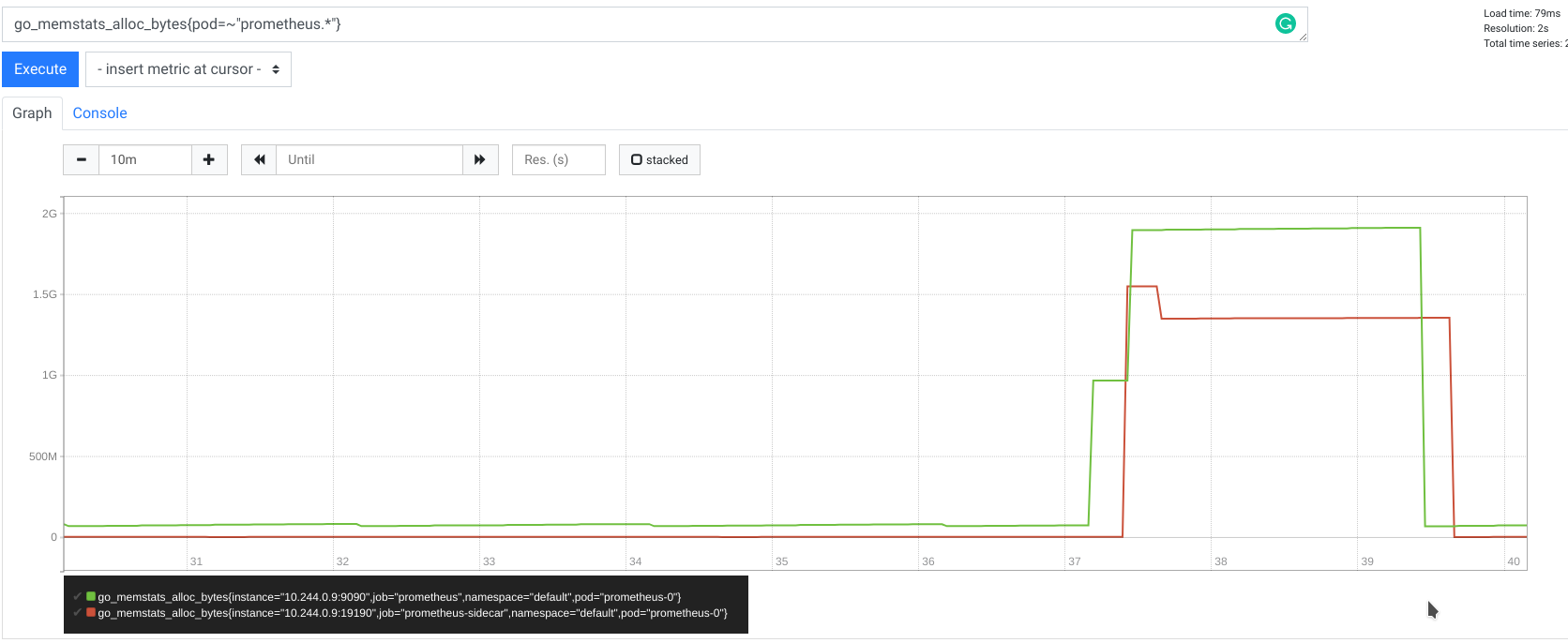
值得注意的是,查询 10,000 个序列不是一个好主意,即使对于 Prometheus 原生 HTTP query_range 端点也是如此,因为您的浏览器会因获取、存储和渲染数百兆字节数据而感到不堪重负。此外,出于仪表盘和渲染目的,拥有如此大量的数据也不实用,因为人类根本无法阅读。这就是为什么我们通常精心设计查询,使其不超过 20 个序列。
这很好,但一个非常常见的技术是以一种方式组合查询,使得查询返回聚合后的 20 个序列,然而在底层,查询引擎必须触及数千个潜在序列来评估响应(例如,当使用聚合器时)。这就是为什么像 Thanos 这样的系统(除了其他数据外,也使用来自远程读的 TSDB 数据)经常出现请求很重的情况。
解决方案
为了解释这个问题的解决方案,了解 Prometheus 在查询时如何遍历数据会有帮助。核心概念可以在 Querier 的 Select 方法返回的名为 SeriesSet 的类型中展示。接口如下所示
// SeriesSet contains a set of series.
type SeriesSet interface {
Next() bool
At() Series
Err() error
}
// Series represents a single time series.
type Series interface {
// Labels returns the complete set of labels identifying the series.
Labels() labels.Labels
// Iterator returns a new iterator of the data of the series.
Iterator() SeriesIterator
}
// SeriesIterator iterates over the data of a time series.
type SeriesIterator interface {
// At returns the current timestamp/value pair.
At() (t int64, v float64)
// Next advances the iterator by one.
Next() bool
Err() error
}
这些接口集合允许进程内部的“流式”流动。我们不再需要拥有一个预先计算好的包含样本的序列列表。通过此接口,每个 SeriesSet.Next() 实现都可以按需获取序列。类似地,在每个序列中,我们也可以通过 SeriesIterator.Next 动态地分别获取每个样本。
通过这个契约,Prometheus 可以最小化分配的内存,因为 PromQL 引擎可以最优地遍历样本来评估查询。同样,TSDB 以一种最优方式实现 SeriesSet,从文件系统中存储的块中逐个获取序列,从而最小化分配。
这对于远程读 API 很重要,因为我们可以通过向客户端发送单个序列的几个块形式的响应片段来重用使用迭代器的流式传输模式。由于 protobuf 没有原生的分隔逻辑,我们扩展了 proto 定义,以允许发送一组小的协议缓冲区消息,而不是单个巨大的消息。我们将此模式称为 STREAMED_XOR_CHUNKS 远程读,而旧模式称为 SAMPLES。扩展协议意味着 Prometheus 不再需要缓冲整个响应。相反,它可以顺序处理每个序列,并在每次 SeriesSet.Next 或一批 SeriesIterator.Next 迭代时发送一个帧,潜在地为下一个序列重用相同的内存页!
现在,STREAMED_XOR_CHUNKS 远程读的响应是一组 Protobuf 消息(帧),如下所示
// ChunkedReadResponse is a response when response_type equals STREAMED_XOR_CHUNKS.
// We strictly stream full series after series, optionally split by time. This means that a single frame can contain
// partition of the single series, but once a new series is started to be streamed it means that no more chunks will
// be sent for previous one.
message ChunkedReadResponse {
repeated prometheus.ChunkedSeries chunked_series = 1;
}
// ChunkedSeries represents single, encoded time series.
message ChunkedSeries {
// Labels should be sorted.
repeated Label labels = 1 [(gogoproto.nullable) = false];
// Chunks will be in start time order and may overlap.
repeated Chunk chunks = 2 [(gogoproto.nullable) = false];
}
如您所见,帧不再包含原始样本。这是我们进行的第二个改进:我们在消息中发送以块为批次的样本(请参阅此视频了解更多关于块的信息),这些块与我们在 TSDB 中存储的块完全相同。
我们最终得到了以下服务器算法
- 解析请求。
- 从 TSDB 选择指标。
- 对于所有序列
- 对于所有样本
- 编码为块
- 如果帧 >= 1MB;中断
- 编码为块
- 编码
ChunkedReadResponse消息。 - 使用 Snappy 压缩
- 发送消息
- 对于所有样本
您可以在此处找到完整设计。
基准测试
这种新方法的性能与旧解决方案相比如何?
让我们比较 Prometheus 2.12.0 和 2.13.0 之间的远程读特性。至于本文开头介绍的初步结果,我使用 Prometheus 作为服务器,使用 Thanos sidecar 作为远程读客户端。我通过使用 grpcurl 对 Thanos sidecar 运行 gRPC 调用来发起测试远程读请求。测试是在我的笔记本电脑(Lenovo X1 16GB, i7 8th)上使用 docker 中的 Kubernetes(使用 kind)进行的。
数据是人工生成的,代表高度动态的 10,000 个序列(最坏情况)。
完整的测试平台可在 thanosbench 仓库中找到。
内存
没有流式传输
使用流式传输
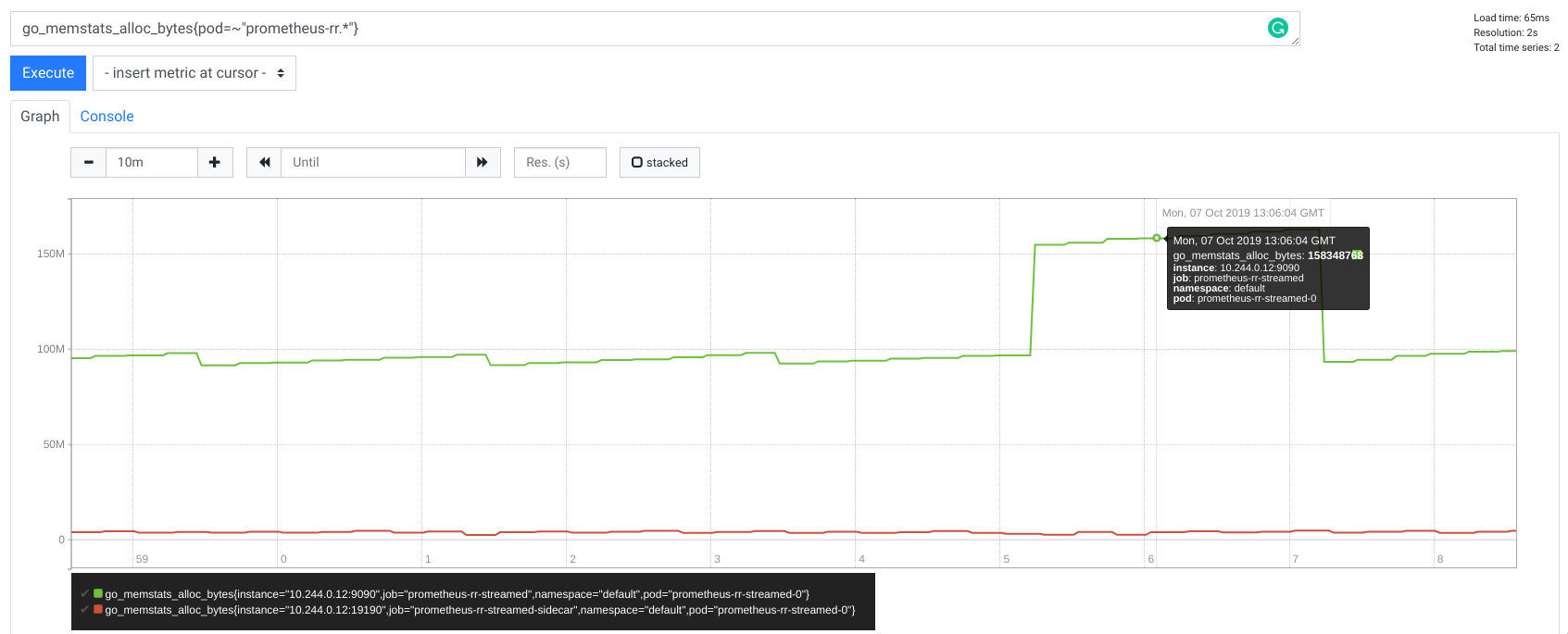
减少内存是我们的解决方案旨在实现的关键目标。Prometheus 在整个请求期间缓冲大约 50MB 内存,而不是分配数 GB 内存,而对于 Thanos,内存使用量微不足道。得益于流式 Thanos gRPC StoreAPI,sidecar 现在是一个非常简单的代理。
此外,我尝试了不同的时间范围和序列数量,但正如预期的那样,Prometheus 的分配内存始终保持在最大 50MB,而 Thanos 的分配内存几乎不可见。这证明了我们的远程读无论您请求多少样本,每个请求使用的内存都是恒定的。每个请求分配的内存也极大地不受数据基数的影响,因此不像以前那样受获取序列数量的影响。
这有助于更轻松地根据用户流量进行容量规划,并借助并发限制。
CPU
没有流式传输
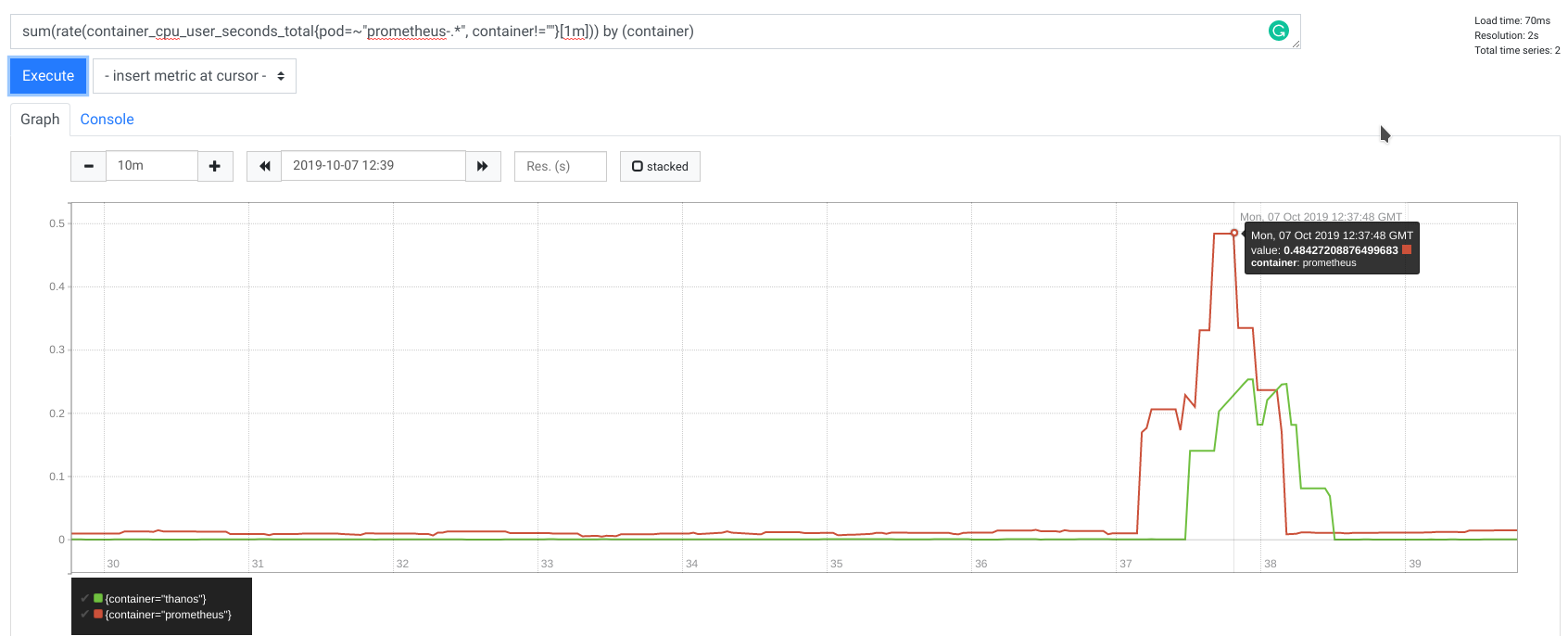
使用流式传输
在我的测试中,CPU 使用率也得到了改善,使用的 CPU 时间减少了 2 倍。
延迟
由于流式传输和减少编码,我们也成功降低了远程读请求延迟。
10,000 个序列的 8 小时范围远程读请求延迟
| 2.12.0:平均时间 | 2.13.0:平均时间 | |
|---|---|---|
| 实际 | 0分34.701秒 | 0分8.164秒 |
| 用户 | 0分7.324秒 | 0分8.181秒 |
| 系统 | 0分1.172秒 | 0分0.749秒 |
以及 2 小时时间范围
| 2.12.0:平均时间 | 2.13.0:平均时间 | |
|---|---|---|
| 实际 | 0分10.904秒 | 0分4.145秒 |
| 用户 | 0分6.236秒 | 0分4.322秒 |
| 系统 | 0分0.973秒 | 0分0.536秒 |
除了延迟降低约 2.5 倍外,与非流式版本(其中客户端延迟仅在 Prometheus 和 Thanos 端处理和编码上就花费了 27 秒(实际时间减去用户时间))相比,响应是立即流式传输的。
兼容性
远程读以向后和向前兼容的方式进行了扩展。这得益于 protobuf 和 accepted_response_types 字段,该字段对于旧服务器来说会被忽略。同时,如果旧客户端不提供 accepted_response_types 参数,服务器也能正常工作,并假定使用旧的 SAMPLES 远程读。
远程读协议以向后和向前兼容的方式进行了扩展
- v2.13.0 之前的 Prometheus 会安全地忽略新客户端提供的
accepted_response_types字段,并假定为SAMPLES模式。 - v2.13.0 之后的 Prometheus 对于未提供
accepted_response_types参数的旧客户端将默认为SAMPLES模式。
用法
要在 Prometheus v2.13.0 中使用新的流式远程读,第三方系统必须在请求中添加 accepted_response_types = [STREAMED_XOR_CHUNKS]。
然后 Prometheus 将流式传输 ChunkedReadResponse 而不是旧消息。每个 ChunkedReadResponse 消息都遵循 varint 大小和固定大小的大端 uint32 用于 CRC32 Castagnoli 校验和。
对于 Go 语言,建议使用 ChunkedReader 直接从流中读取。
请注意,storage.remote.read-sample-limit 标志对于 STREAMED_XOR_CHUNKS 不再起作用。storage.remote.read-concurrent-limit 像以前一样工作。
还有一个新选项 storage.remote.read-max-bytes-in-frame 控制每条消息的最大大小。建议将其保持为默认值 1MB,因为 Google 建议 protobuf 消息不大于 1MB。
如前所述,Thanos 通过这项改进获益良多。流式远程读已添加到 v0.7.0 中,因此此版本或任何后续版本在使用 Prometheus 2.13.0 或更新版本与 Thanos sidecar 配合时,将自动使用流式远程读。
后续步骤
2.13.0 版本引入了扩展远程读和 Prometheus 服务器端实现,然而在撰写本文时,仍有一些工作要做,以便充分利用扩展的远程读协议
总结
总而言之,分块流式远程读的主要好处是
- 客户端和服务器都能够实现每个请求几乎恒定的内存大小。这是因为 Prometheus 在远程读期间一次只发送单个小帧,而不是整个响应。这极大地有助于容量规划,特别是对于内存这种不可压缩的资源。
- Prometheus 服务器在远程读期间不再需要将块解码为原始样本。对于客户端的编码也是如此,如果系统重用了原生的 TSDB XOR 压缩(如 Thanos 所做)。
一如既往,如果您有任何问题或反馈,请随时在 GitHub 上提交工单或在邮件列表中提问。